AI 기술의 발전으로 인류는 그 어느 시대보다도 정보에 가장 쉽게 접근할 수 있지만, 그 중에서 양질의 정보를 찾아내기 가장 어려운 시대에 도래했다고 생각된다. 그래서 디지털 리터러시를 키우기 위해 앞으로 퇴근 후 짬짬이 책을 한두 권씩 볼 예정..!
벌써 4일간 4권이나 읽었다.
독후감 - 부의 추월차선 후기
일단 이 책에 대해 찾아보니 불쏘시개에 비유할 정도로 논란이 많은데 많은 사람들의 인생 방식이 틀렸다고 하는 자극적인 내용과 "나는 이렇게 하니 되었다."라는 성공 스토리가 대다수라 좀 거부감이 들 수 있다고 생각된다. 책을 읽으며 얻을 건 얻고 필요 없는 부분은 버리는 식으로 생각하자.
책의 저자는 가난한 어린 시절을 보냈는데, 어느 날 람보르기니를 몰던 자수성가한 사람을 발견하고 큰 깨달음을 얻었다고 한다. 그래서 젋었을때 백만장자가 되는 방법을 연구했고, 바로 행동으로 옮겨서 큰 부를 얻었다.
이 과정에서 깨달은 부자가 되는 공식을 제시한다.
부자가 되는 공식
1. 지도 (나아가야 할 방향)
2. 차량 (자기 자신)
3. 속도 (생각을 행동으로 옮기는 추진력)
여기서 가장 중요한것은 부자까지 가는 지도이다.
사람들은 크게 3가지 방식을 이용한다고 제시한다.
1. 인도로 가는 지도
돈을 잘 벌든 말든 상관 없이 재무적 목적지가 존재하지 않는 사람으로, 하루 벌어 하루 쓰는 사람들을 뜻한다.
어떤 팝스타의 한 달 소득이 40만 달러였지만 수입이 바로 끊기자 파산하는 케이스를 예시로 들었다.
2. 서행차선으로 가는 지도
재무적 지식은 있지만 늙어서 부자가 되는 사람들을 뜻한다.
대부분의 제태크 책들은 부동산, 주식 등에 30~40년 투자해서 여유로운 은퇴생활을 즐기도록 부추기는데 저자는 늙어서 돈을 벌면 무슨 소용이 있냐고 젋은 나이에 돈을 불려야한다고 주장한다. (이 내용은 3번에 후술)
또한, 절약으로는 절대로 부자가 될 수 없다고 말하면서 지출보다는 소득을 늘려야 한다고 주장한다.
3. 추월 차선으로 가는 지도
직장은 시간을 팔아 돈을 얻는 방법이라고 소개하면서 저자는 부자는 시간으로부터 자유롭고, 돈으로부터 자유로운 사람을 뜻한다고 한다.
이를 위해 저자는 창업을 추천하는데, 내가 일하는게 아니라 나를 위해 일하는 사람을 고용하고, 내가 일을 하지 않아도 시스템이 자동으로 돈을 벌어오는 현금 흐름을 만들어야 한다고 주장한다.
예시로 저자는 웹 페이지를 만들어 자동적으로 나오는 광고 수입으로 큰 소득을 올렸고, 끝내는 다른 회사에 팔아 큰 수익을 챙겼다고 한다.
혹은 창업 외에도 발명, 개발 등 현금 흐름을 기하급수적으로 발생시키는 어려가지 방법을 제시한다.
결론
보통 재테크 책이라고 하면 2번인 서행차선 방식을 추천하고, 부동산 주식 채권 등 금융 자산으로 현금 흐름을 늘리라는 식의 추천을 하는데
이 책은 하이리스크 하이리턴인 창업을제시하다니.. 부자가 되는 방식은 쉽지 않구나 생각이 든다.
이 책에서 취할 수 있는 것은 다음과 같다고 생각된다.
- 일을 안해도 자동으로 현금 흐름이 생기는 시스템을 생성해라.
- 많은 일 => 많은 소득이 아니라 많은 일 => 더 많은 일이다.
또한, 저자가 부자가 된 방식인 코딩을 나는 운좋게도 전공으로 삼았고, 할 수 있다. 창업 이외에도 사이드 프로젝트등 여러 방법을 사용 할 수 있지 않을까?
사이드 프로젝트를 위해 chatgpt api를 사용해 보던 중 최근 신기한 기능을 찾아서간단히 요약해본다.
gpt에게 어떤 '상황'을 부여하고, 문맥을 기억할 수 있게 하는 assistant api가 새로 생겼다.
이를 통해 chatgpt를 프롬프트 엔지니어링을 통해 자신이 원하는대로 커스텀 가능하게 되었는데
국내엔 관련 자료가 많지는 않은거 같아서 기록겸 요약해본다.
gpt store에 올리는 custom gpt가 이 assistant와 비슷한 개념일듯?
사전 지식
chatgpt에게 api로 명령을 보낼때는 message role로 "user", "assistant", "system"을 보내어 원하는 명령을 수행시킨다.
'user'는 유저가 입력한 명령을 의미한다.
'system'은 chatgpt에게 입력할 제약 사항, 요구 사항 등을 의미한다.
'assistant'는 명령을 수행하기 위한 앞뒤 문맥, 사전 지식등을 뜻한다.
api example)
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
}'
기존 api는 독립적으로 작동하기 때문에 앞뒤 문맥을 파악하지 못했다.
이를 위해서 assistant role로 이전의 대화 내용을 전부 보내주거나 요약해줘야 했고, 이는 api의 과다 사용 = 비용의 상승으로 이어졌다.
assistant api는 이 문제를 해결하기 위해서 미리 학습시킨 system, assistant 값을 이용해 유저의 api 명령을 처리한다.
이를 위해서 assistant는 text 파일 같은 file 입력도 가능하며 model 의 튜닝도 가능하다.
2. Thread
명령이 이루어지는 "context", 대화 맥락을 뜻한다.
채팅방이라고 생각하면 될 듯하다.
Thread간의 context는 독립적이다. 이 말은 즉, 카카오톡 1:1 채팅방처럼 여러 thread가 있을 수 있다.
3. Message
기존의 chatgpt api message와 동일하다.
assistant api에선 thread 단위로 message간의 대화 맥락, context를 파악해서 ai가 대화를 이어나가준다.
4. RUN
run의 결과값
message를 입력한 이후의 결과 객체이다.
코드 레벨에서 의미 있는 객체인데 뭔 역할인지 코드 예시에서 후술함
여기서 api를 사용하기 위해서 assistant, thread, message를 어떻게 코드 레벨에서 동작시키는지 좀 혼란을 겪었는데 사이드 프로젝트의 코드 예시로 설명하겠다.
개인적으로는 상당히 복잡하고, chat gpt한테 보낸 명령이 완료되었는지 확인하기 위해서
pooling을 써야하는 부분이 있어서 비동기 처리 측면에서 상당히 헷갈렸던듯..?
지금 next14에서 실험중이니 next 코드로 설명함
전체 코드는 아래와 같다.
/* eslint-disable no-await-in-loop */
import { NextRequest, NextResponse } from 'next/server'
import { OpenAI } from 'openai'
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
async function handler(req, res) {
try {
const body = await req.json()
const assistant = await openai.beta.assistants.retrieve(' assistant api id 추가! ') // TO DO - tutor 별로 assistant 생성
const thread = await openai.beta.threads.retrieve('thread api id 추가 !') // TO DO - 유저 대화창별로 thread 생성
const { excelJSON, prompt } = body
const message = await openai.beta.threads.messages.create(thread.id, {
role: 'user',
content: prompt,
})
const run = await openai.beta.threads.runs.create(thread.id, {
assistant_id: assistant.id,
})
let cnt = 0
// TO DO - polling logic 업그레이드
while (cnt < 1000) {
const { status } = await openai.beta.threads.runs.retrieve(thread.id, run.id)
if (status === 'completed') break
await new Promise((resolve) => {
setTimeout(() => {
resolve(1)
}, 500)
})
cnt += 10
}
const messages = await openai.beta.threads.messages.list(thread.id)
// @ts-ignore
const responseText = messages.data[0].content[0].text.value
console.log(JSON.stringify(responseText), responseText)
... 생략(뒤는 중요하지 않은 파트임)
}
export { handler as POST }
1. assistant와 thread 불러오기
/* eslint-disable no-await-in-loop */
import { NextRequest, NextResponse } from 'next/server'
import { OpenAI } from 'openai'
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
async function handler(req: NextRequest, res: any) {
try {
const body = await req.json()
const assistant = await openai.beta.assistants.retrieve(' assistant api id 추가! ') // TO DO - tutor 별로 assistant 생성
const thread = await openai.beta.threads.retrieve('thread api id 추가 !') // TO DO - 유저 대화창별로 thread 생성
const { excelJSON, prompt } = body
앞 부분은 미리 생성된 assistant를 불러오고, 기존에 채팅방(thread)를 불러오는 api이다.
어시스턴트와 thread는 코드 레벨에서도 구현이 가능하고 혹은 playground에서도 생성이 가능하다.
숨김 처리한 부분이 각각 assistant id, thread id이다.
2. message 전달 후 chatgpt 실행
const message = await openai.beta.threads.messages.create(thread.id, {
role: 'user',
content: prompt,
})
const run = await openai.beta.threads.runs.create(thread.id, {
assistant_id: assistant.id,
})
// TO DO - polling logic 업그레이드
while (cnt < 1000) {
const { status } = await openai.beta.threads.runs.retrieve(thread.id, run.id)
if (status === 'completed') break
await new Promise((resolve) => {
setTimeout(() => {
resolve(1)
}, 500)
})
cnt += 10
}
message를 생성하고 chatgpt에게 실행시킨다.
만약 message 결과값을 확인하고 싶다면 pooling api를 통해 대화가 끝났는지 체크해줘야 한다..
run의 결과는 아까 보았던 completed, failed, canceled 등등이 있다.
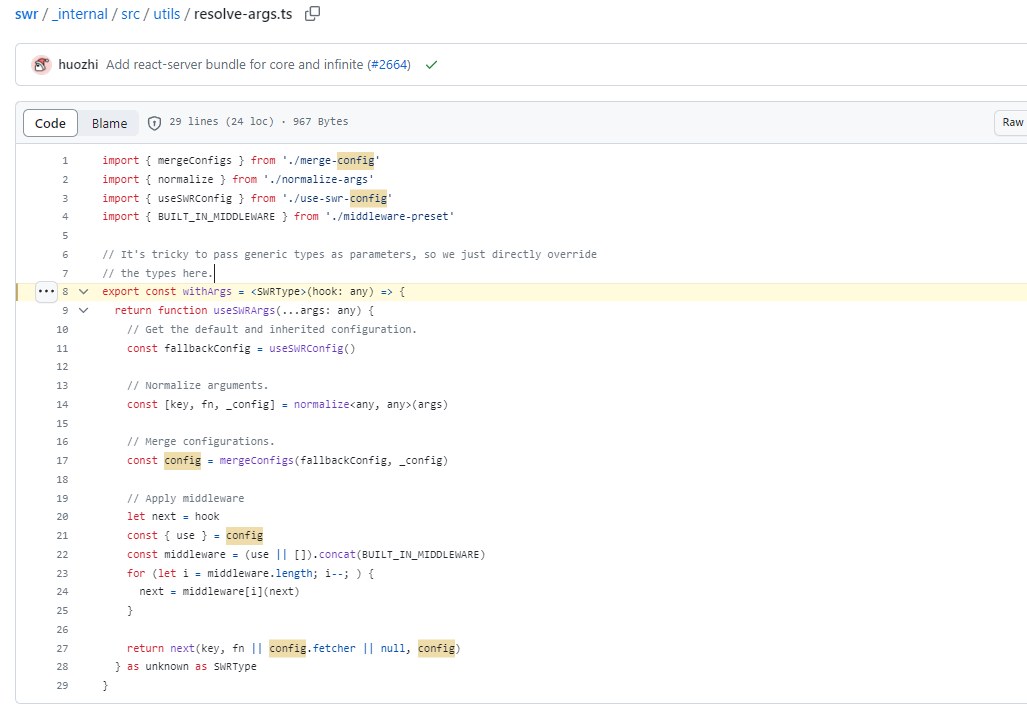
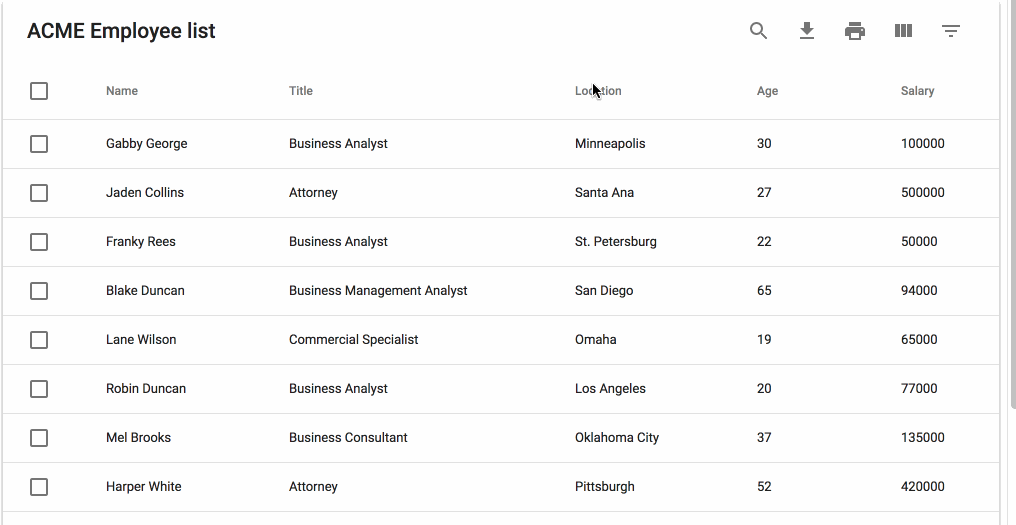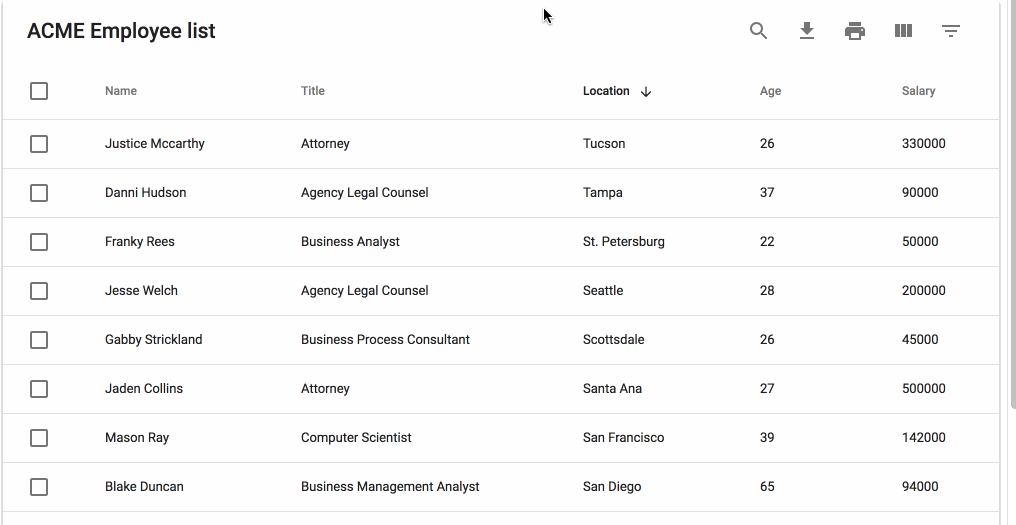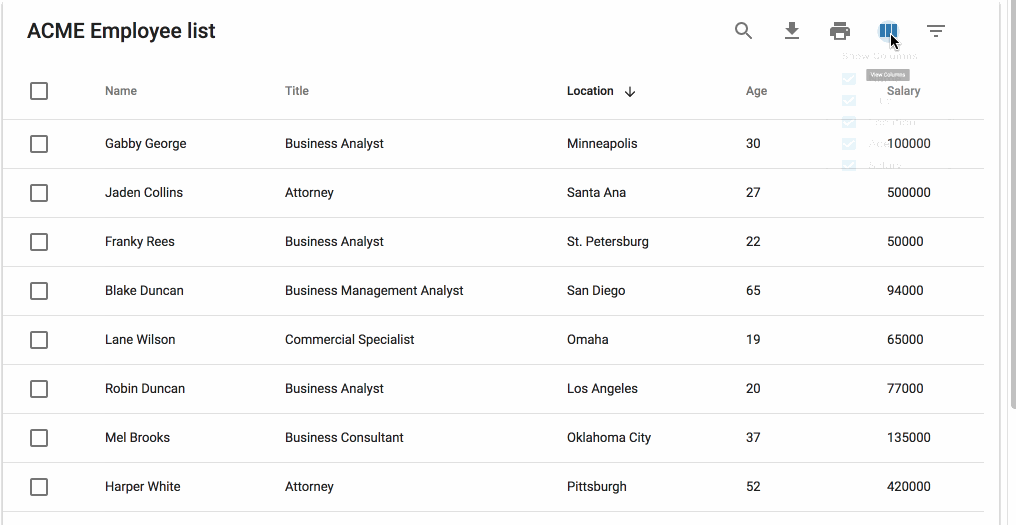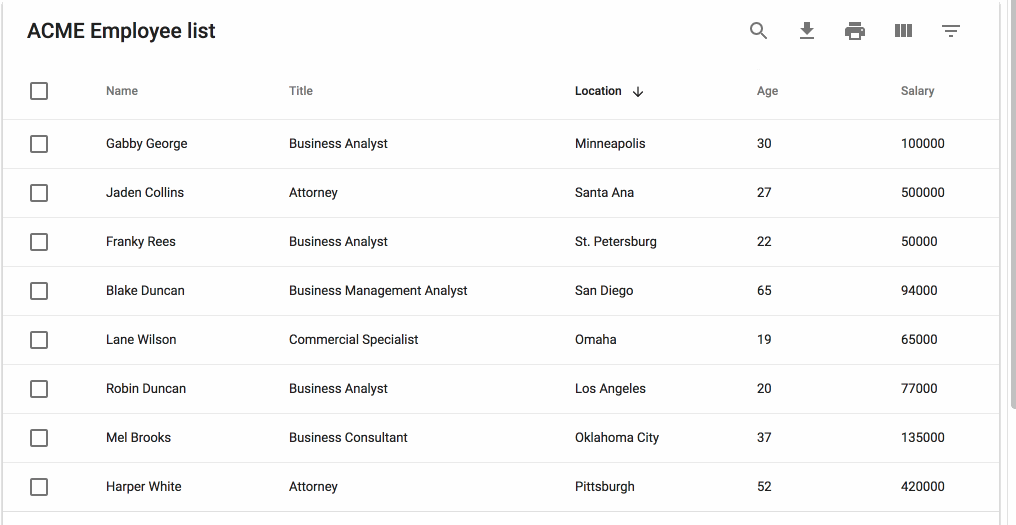
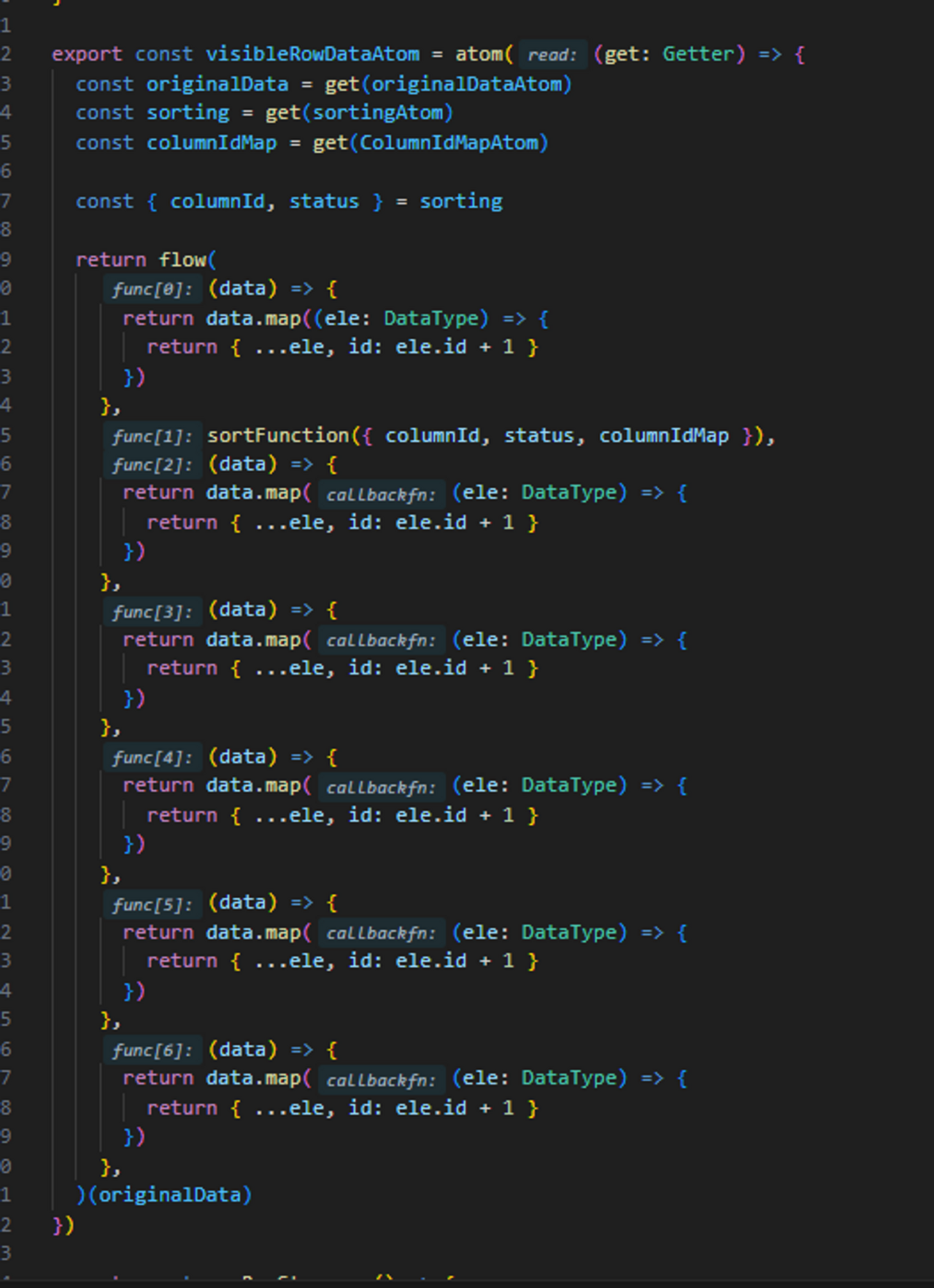
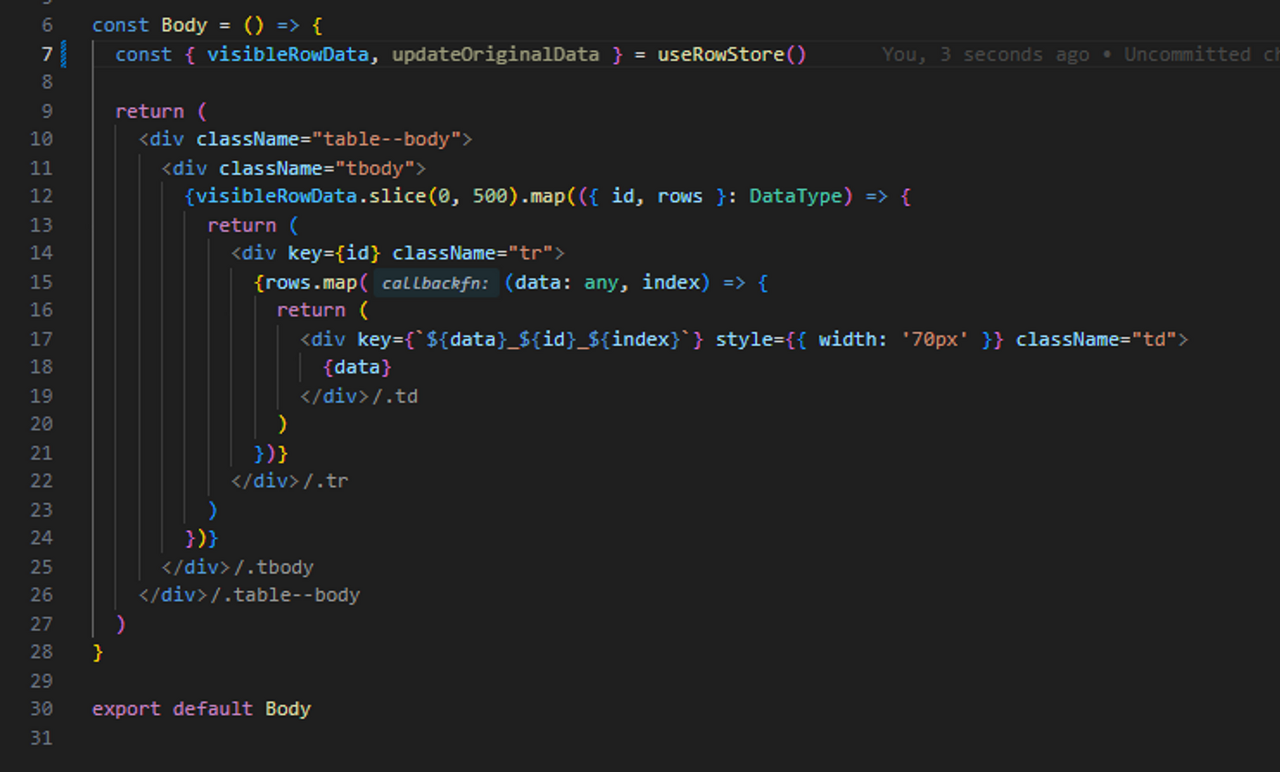
테이블 라이브러리의 케이스에서는 Option이 넘어올때 중간에서 Nullable한 값이 있다면 default 값으로 overwrite하면 됐었다. 실제로 swr 라이브러리도 config로 넘긴 값을 defaultConfig과 merge해서 overwriting 하는 방법을 쓰고 있다. (17번째 줄)
옛날에 부스트캠프를 했을때 모든 코드에 null체크를 하는 게 안좋다는 피드백을 멘토님께 받았었는데
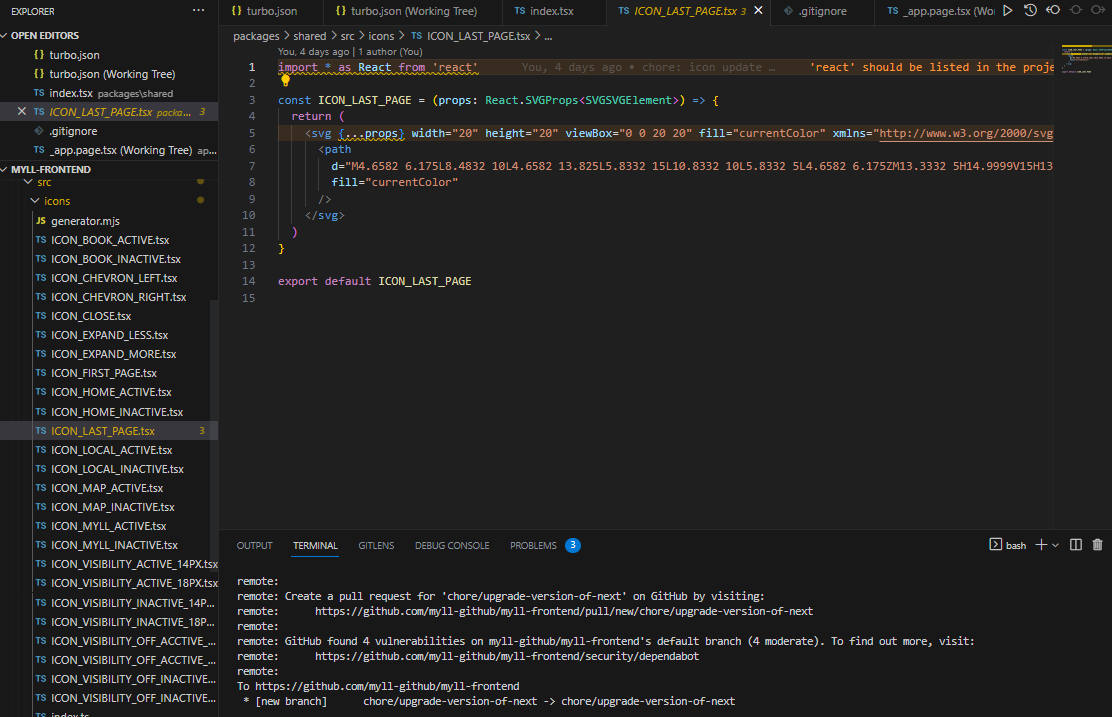
1. 디자이너가 피그마에서 업데이트한 아이콘을 내려받은 후, 이를 압축합니다.
2. 사내 메신저에 업로드하고, 엔지니어에게 공유합니다.
3. 엔지니어는 이를 내려받아 압축을 풀고, 소스 코드에 적절히 추가합니다.
4. PR을 올려 코드 리뷰 후 머지합니다.
// (https://channel.io/ko/blog/figma-icon-plugin) 에서 발췌
그래서 피그마에서 아이콘 업데이트가 이뤄진다면 코드에서 바로 다운받을 수는 없을까? 생각했고,
찾아본 결과 피그마 plugin을 발견하여 직접 써본 후 사용 방식을 공유해본다.
사용방법
1. 피그마 access token 추가
figma setting > personal access token에서 토큰을 생성한다.
피그마 web api를 사용하려면 access token을 같이 보내줘야 한다.
2. node-fetch 설치
pnpm add -D node-fetch //pnpm, yarn, npm 등 사용하는걸로 설치
asyncfunctionrun() {
if (!TOKEN) {
console.error(
'The Figma API token is not defined, you need to set an environment variable `FIGMA_API_TOKEN` to run the script',
)
return
}
fetchFigmaFile(FILE_KEY)
.then((data) => getComponentsFromNode(data.document))
.then(getSVGsFromComponents)
.then((dataArray) => dataArray.map(generateFiles))
.then((ele) =>Array.from(newSet(ele)))
.then((texts) => {
writeFileSync(
'./src/icons/index.ts',
texts.reduce((t, v) =>`${t}\n import ${v} from './${v}'`, ''),
)
appendFileSync('./src/icons/index.ts', texts.reduce((t, v) =>`${t}${v},`, '\n\n export {').slice(0, -1))
appendFileSync('./src/icons/index.ts', '}')
})
}
run()
빌드된 tttable(임시 작명이라 가명임;;) 레포의 index.js를 required 하면 오류가 나는것
평소에 commonjs와 esm, amd 등이 뭔지 헷갈려서 이참에 정리겸 간단하게 요약해본다.
CommonJS(CJS)란?
// 모듈 정의
const circle = require('./circle.js');
const radius = 5;
console.log(`반지름 ${radius}인 원의 넓이: ${circle.area(radius)}`);
console.log(`반지름 ${radius}인 원의 둘레: ${circle.circumference(radius)}`);
JavaScript를 위한 모듈 로딩 시스템 표준 중 하나이다.
Node.js와 같은 서버 측 JavaScript 환경에서 사용되며, 모듈을 정의하고 로드하기 위한 표준화된 방법을 제공한다.
node.js나 프론트엔드의 config 파일에서 많이 본 require를 사용한 방식이 commonJS 방식이다.
초기 Javascript는 모듈 시스템이 없었기 때문에 모듈화를 위해 commonJS, AMD 등이 개발되어 사용되었다.
commonJS는 동기적으로 모듈을 로드하기 위해 사용되고,
비동기를 따로 다루기 위해 AMD(Asynchoronous Module Definition)이 비동기적으로 모듈을 다루는 것에 대한 표준안으로 제시되었다고 한다.
ECMAScript Module(ESM)이란?
// 모듈 불러오기
import circle from './circle.mjs';
// 모듈 사용
const radius = 5;
console.log(`반지름 ${radius}인 원의 넓이: ${circle.area(radius)}`);
console.log(`반지름 ${radius}인 원의 둘레: ${circle.circumference(radius)}`);
ES6부터 표준화 된 모듈 시스템으로, 클라이언트에서 흔히 사용하는 import, export를 사용하는 방식이다.
브라우저에서 사용하기 위해서는 type="module"을 script 혹은 package.json에 명시해주면 된다.