최근 취직한 직장에서 실시간 모니터링 툴을 만들고 있다.
결론부터 말하자면 월부터 3월까지 일하면서
(실시간 데이터 업데이트시) 렌더링 시간을 700~600ms에서 390~290ms로 대략 100% 개선하였다.
이때 사용한 기법을 간단하게 적어보고자 한다.

실제 제품과 코드를 보여줄순 없고 비슷한 제품으로는 그라파나(https://grafana.com/) 라는 제품이 있는데 거의 80%쯤 비슷해서..? 이 제품을 보여주고 예시로 설명하고자 한다.
react-grid-layout(https://github.com/react-grid-layout/react-grid-layout)이라고 레이아웃 배치때 사용한 라이브러리도 똑같다.
배경 지식
어떻게 개선했나 리펙토링을 설명하기에 앞서
어떤 구조로 되어있나를 간략하게 설명하고자 한다.

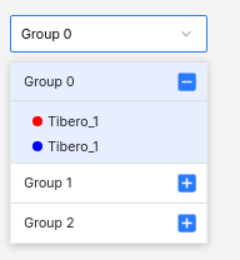
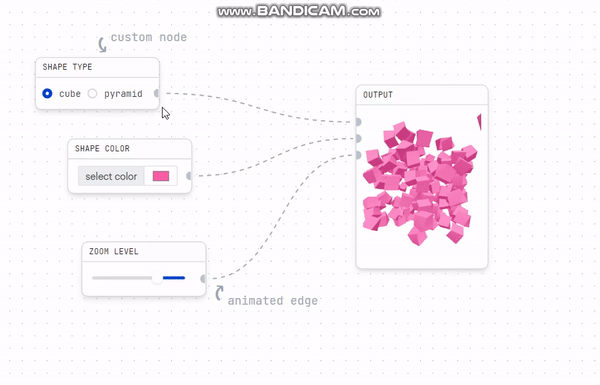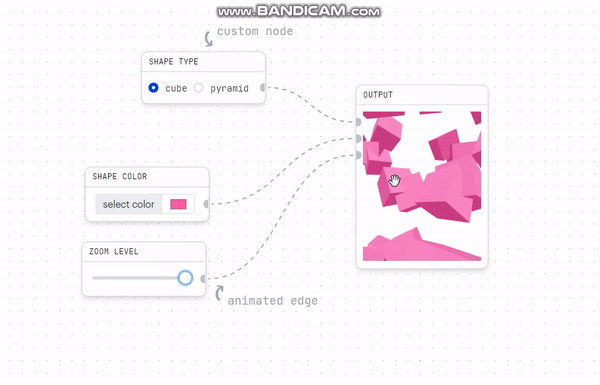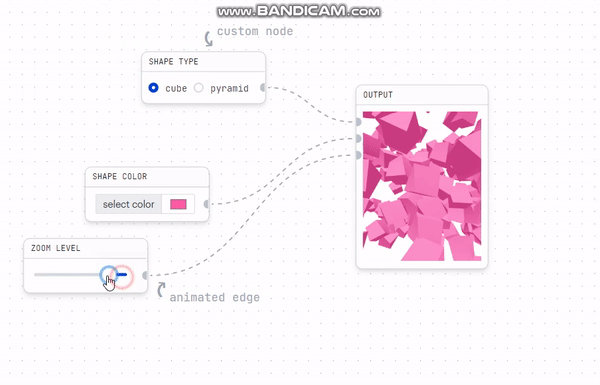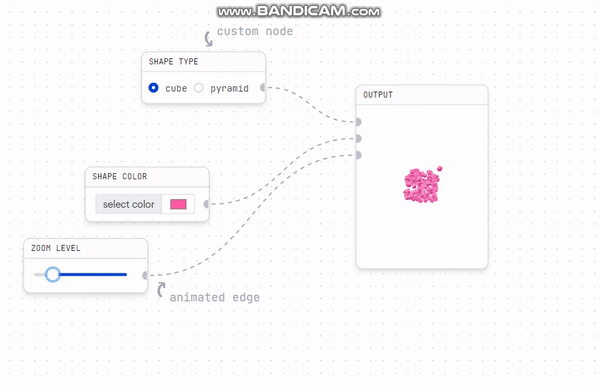
화면에는 두가지 api 정보가 있다.
1. layout 정보 (빨간색) : 전체 레이아웃 정보와 레이아웃과 관련된 차트 정보를 담고 있다.
레이아웃 좌표(x, y축), 차트 종류(area, grid, bar 등) 차트를 각각 '어디'에 배치할지 정보를 담고 있다.
2. chart 정보(파란색) : 차트 내부의 실제 차트 정보를 api를 통해 불러온다.
프로젝트는 CRA로 구현되었는데 해당 화면을 들어가게 되면 1차적으로 layout정보를 api를 통해 불러오고,
레이아웃을 불러오면 2차적으로 각각 차트 데이터를 api를 통해 불러오게 되는 구조다.
문제 원인
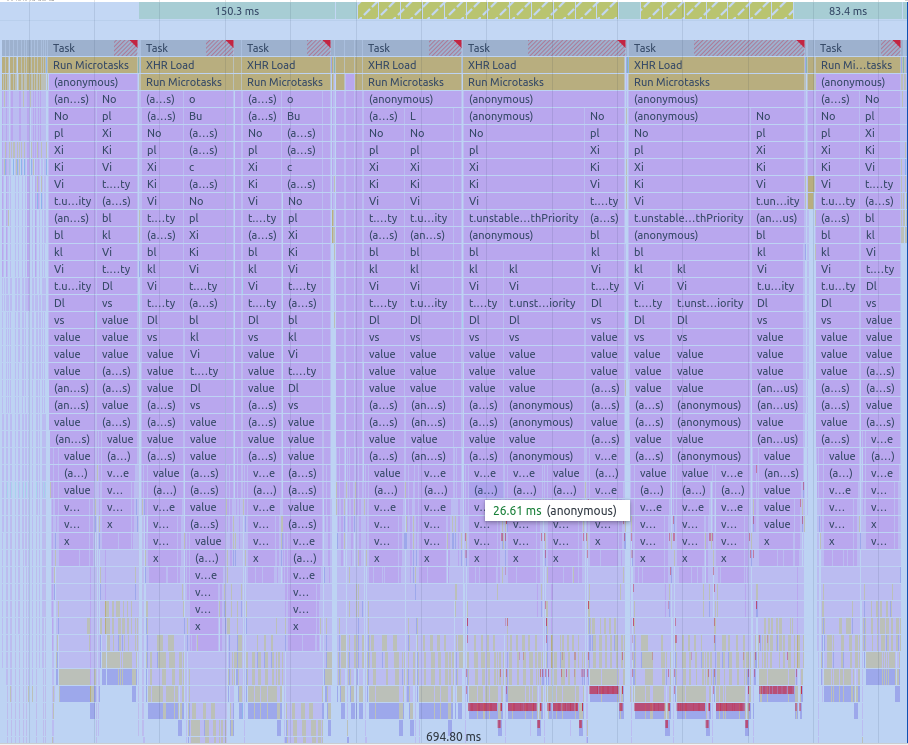
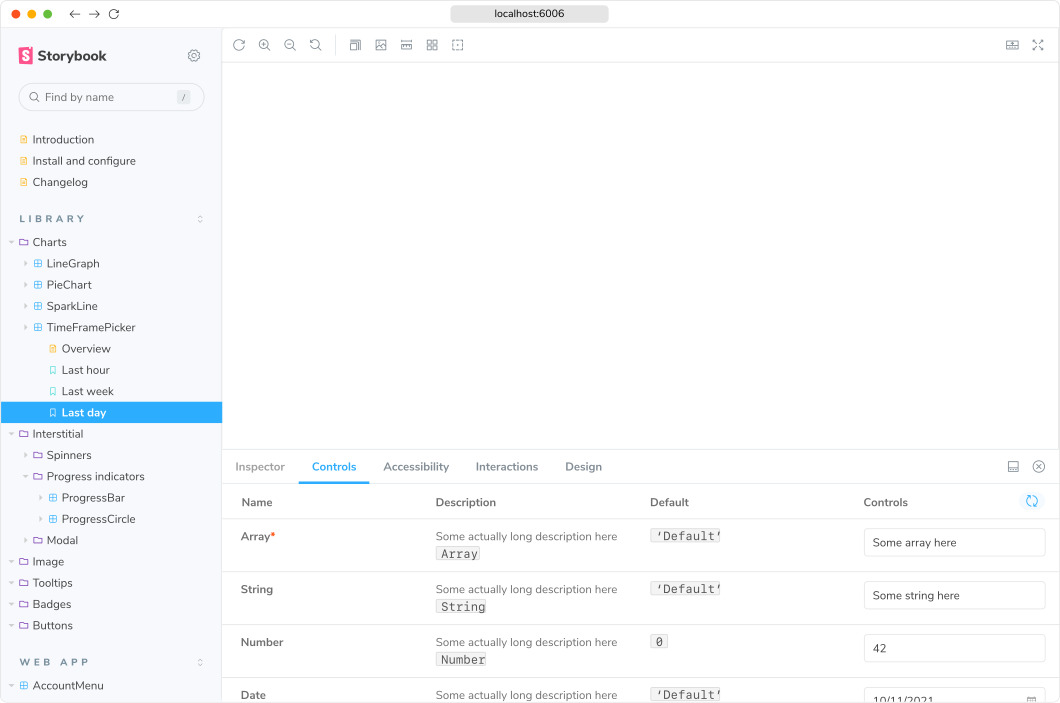
react profiler를 돌려본결과 느린 이유를 크게 아래의 3가지로 압축가능한듯하다.
설명하고 추후 해결방안을 제시할 예정
1. presentational and container pattern 이용
전체 페이지가 presentational and container pattern으로 구현되어 있고 로직이 최상위에 몰려있었다.
최상층에서 layout 정보를 받아 상태로 가지고 있고 (mobx + useState 혼합) 부모 컴포넌트가 리렌더링되면 자식 컴포넌트도 자동적으로 전부 리렌더링되는데 하나만 바뀌어도 화면 전체 리렌더링을 유발했다.
전임자가 Memo등을 사용해서 최적화를 시도한듯한데 신통치는 않았던듯..
끔찍한 가독성은 덤이고 이 구조는 재앙(?)을 불러오게 된다. 2번에서 후술
2. derived State 사용
class EmailInput extends Component {
state = { email: this.props.email };
render() {
return <input onChange={this.handleChange} value={this.state.email} />;
}
handleChange = event => {
this.setState({ email: event.target.value });
};
componentWillReceiveProps(nextProps) {
// This will erase any local state updates!
// Do not do this.
this.setState({ email: nextProps.email });
}
}
코드 예시 - 리엑트 공식 링크 참고 (https://reactjs.org/blog/2018/06/07/you-probably-dont-need-derived-state.html)
derivedState란 말 그대로 상태로부터 파생되는 State이다.
위 코드 예시처럼 prop으로 어떤 상태를 내려받아 전처리나 필요한 데이터만 따로 빼내어 상태로 관리하는 형태이다.
기존 코드에서는 presentational-container 패턴으로 layout api 정보를 최상층에서 prop으로 주입하고,
차트 내부에서 derived state를 사용해서 chart api 데이터와 혼합해 관리했다.
아까 캡처 사진을 보면서 다시 이해해보자.
layout api state(빨간색)에는 모든 레이아웃의 정보가 담겨 있다.
chart 레이아웃 정보는 array 형식으로 담겨 있는 형태였는데
chart 내부에서 layout의 정보를 사용하려고 chart api state(파란색)과 혼합해 전처리하고
derivedState를 만들게 된다.
위 렌더링 profiler를 보면 Run MicroTask란 작업이 엄청 많은것을 볼 수 있는데
어떤 상태가 바뀌면 derivedState도 재생생하면서 rerendering을 무수히 많이 발생시켜 렌더링 속도가 매우 느려지게 된다.
예를 들어, 파란색 chart를 오른쪽으로 약간 이동시키기만 해도 최상층부터 맨 아래까지 수많은 렌더링이 발생하는것...
처음엔 Run MicroTasks라길래 네트워크 중복 호출인줄 알았는데 아니였고
수많은 useEffect와 derivedState 문제인것으로 추측된다.
3. api 호출때 Batching 처리 X
각 레이아웃에서 chartData를 api로 호출할때 한번에 묶어 호출하는게 아니라
차트 하나하나가 api콜을 해서 렌더링시키게 된다.
30개의 차트면 30개의 api 콜을 하는 방식인데
한두개가 네트워크 지연으로 느리게 오게 되면 다시 리렌더링을 발생시키게 된다.
해결 방안
리펙토링에서는 위 3가지 문제점을 제거하는 방안으로 일단 리펙토링을 진행했다.
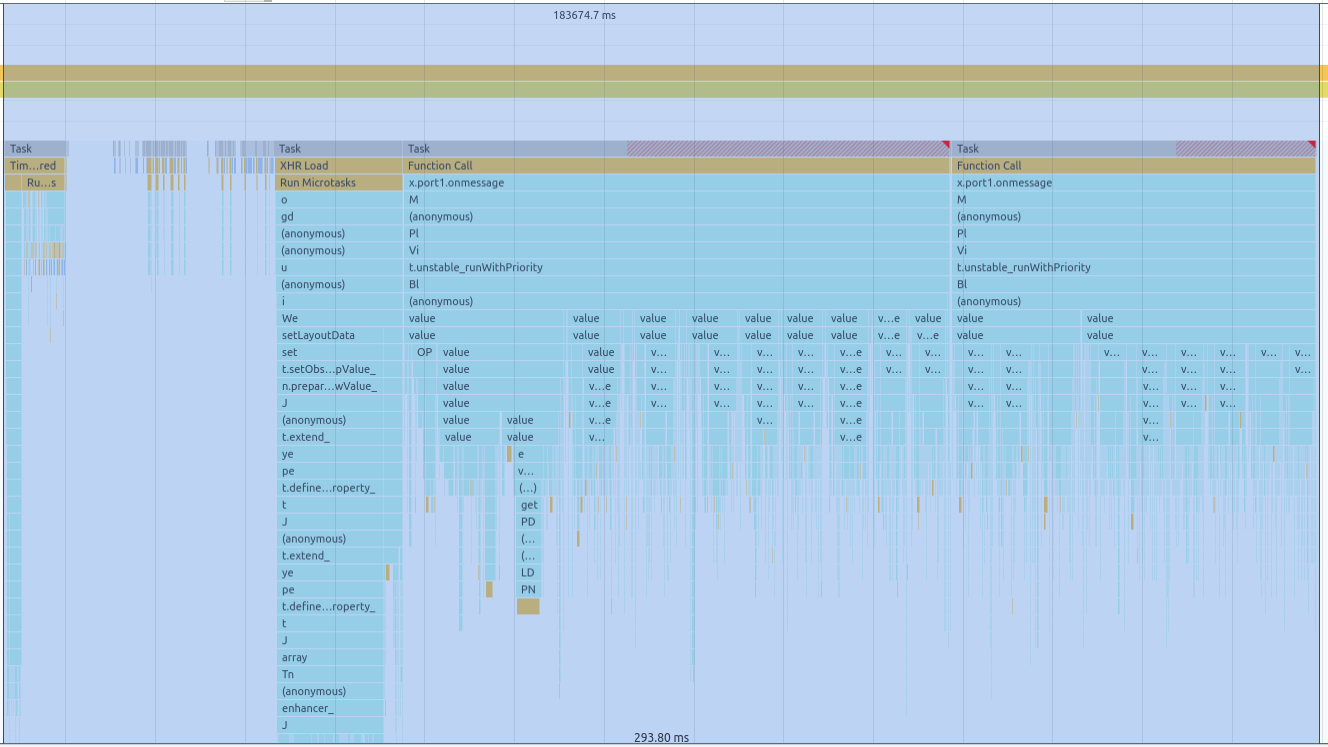
그래서 이후 점진적인 리펙토링이 필요함에도 일단 상당히 빨라진것을 볼 수 있다.
1. presentational and container pattern 이용 -> Hook + 전역 State 방식으로 변경
전역 state를 사용하면 변경된 상태들과 관련된 react component들만 리렌더링 시킬 수 있다.
1번은 사실 pattern 문제라기보다는 가독성 + 2번 문제 해결을 위해 리펙토링했다.
2. derived State 제거
정확히는 불필요한 rerendering을 줄이기 위해서 UseEffect를 제거했고,
UseEffect가 필요한 derived state를 제거했다.
derived State를 사용한 이유를 보니
복잡한 3~4 depth의 api를 전처리해 chart 내부에서 사용하려는 이유도 크길래
'전처리'해야하는 상태를 normalizr로 따로 분리하여 1 depth로 전처리후 전역 state로 관리하고
chart에 각각 unique한 id를 발급하여 전역 state를 id로 접근할 수 있게 리펙토링했다.
setState({
locateX : props.layoutData.properties.x;
locateY : props.layoutData.properties.y;
threshold: props.layoutData.properties.y;
chartData : chartData.data.chartData;
chartAxisX : chartData.data.axisX,
chartAxisY : chartData.data.axisY,
....
})이렇게 사용하던 코드를 (실제 코드와는 다른 예시 코드임)
const {locateX, locateY, threshold, chartData, chartAxis, chartAxisY } = useLayoutData(props.chartId);normalizr를 사용해 위와 같이 리펙토링했다.
3. Batching처리 로직 추가
const promise1 = Promise.resolve(3);
const promise2 = new Promise((resolve, reject) => setTimeout(reject, 100, 'foo'));
const promises = [promise1, promise2];
Promise.allSettled(promises).
then((results) => results.forEach((result) => console.log(result.status)));
// Expected output:
// "fulfilled"
// "rejected"promise.allSettled()를 사용하면 위와 같이 여러개의 api콜이 다 올때까지 await를 걸 수 있고, 에러처리도 해준다.
각 차트에서 api 콜을 하는게 아니라, 배칭처리를 통해 모든 api콜이 올때까지 기다린후
한번에 chart들을 업데이트해주는 방식으로 변경했다.
해당 방식만을 사용하면 chart가 하나 추가되었을때 다시 모든 api 콜을 하는 단점이 있었는데
이것은 requestTime을 기록해서
현재시간-refreshTime >= refresh로
필요한 데이터만 불러오도록 예외처리시켰다.
다음 분기에는 모든 api를 하나로 통합하고 마치 GraphQL처럼(혹은 graphQL로)
프론트에서 질의문을 보내 필요한 데이터만 받아오는 형식으로 변경하지 싶은데 일단은 배칭처리로 묶는거까지 마무리했다.
여담으로 이 페이지를 만든 전임자가 내가 입사하기 전에 나간 상태여서
걍 맨땅에 헤딩하는식으로 했기 때문에 코드 이해에 애좀 먹었다;;
지금 생각해도 이걸 신입이 어떻게 했지? 싶은데
못했으면 짤렸으려나?
'Front-end > work' 카테고리의 다른 글
| Null 전파를 막자 (0) | 2023.11.04 |
|---|---|
| Tanstack Table Library 코드를 까보자 (1) | 2023.10.27 |
| 대용량 react 테이블을 만들어보자 (7) | 2023.09.16 |
| 피그마 아이콘 자동 다운 받기 (2) | 2023.08.05 |
| 리엑트 레거시 프로젝트 개선기 (0) | 2023.02.04 |