반응형
연구실 다닐때 resnet 구조를 desnet으로 변경하면 어느정도 성능이 향상되나? 실험해본 보고서
결과 : 0.4% 정도 향상
(학부생의 분석 결과라 잘못된 내용이 있으면 피드백 주시면 감사하겠습니다)
반응형
'인공지능' 카테고리의 다른 글
| chat gpt assistant api 써보기 (feat: 예제 코드) (1) | 2024.01.21 |
|---|
| chat gpt assistant api 써보기 (feat: 예제 코드) (1) | 2024.01.21 |
|---|
->
1. 동일 계열의 알고리즘을 정의하고
동적으로 행위의 수정이 필요한 경우
전략을 바꾸는것으로 행위의 수정이 가능하게 만드는 패턴

example
public class StrategyPatternWiki
{
public static void Main(String[] args)
{
Customer firstCustomer = new Customer(new NormalStrategy());
// Normal billing
firstCustomer.Add(1.0, 1);
// Start Happy Hour
firstCustomer.Strategy = new HappyHourStrategy();
firstCustomer.Add(1.0, 2);
// New Customer
Customer secondCustomer = new Customer(new HappyHourStrategy());
secondCustomer.Add(0.8, 1);
// The Customer pays
firstCustomer.PrintBill();
// End Happy Hour
secondCustomer.Strategy = new NormalStrategy();
secondCustomer.Add(1.3, 2);
secondCustomer.Add(2.5, 1);
secondCustomer.PrintBill();
}
}->
요청 자체를 캡슐화
실행될 기능을 캡슐화해 기능 실행을 요구하는 호출자와 실제 기능을 실행하는 수신자 클래스 사이의 의존성 제거
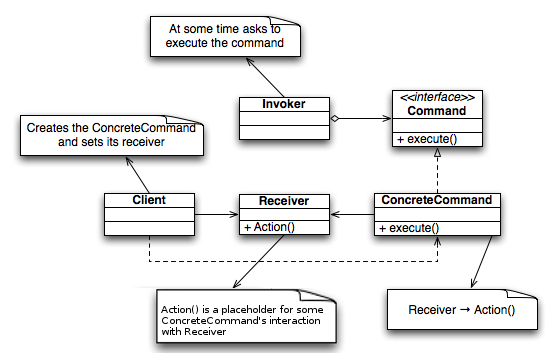
/*the Invoker class*/
public class Switch {
private Command flipUpCommand;
private Command flipDownCommand;
public Switch(Command flipUpCmd,Command flipDownCmd){
this.flipUpCommand=flipUpCmd;
this.flipDownCommand=flipDownCmd;
}
public void flipUp(){
flipUpCommand.execute();
}
public void flipDown(){
flipDownCommand.execute();
}
}
/*Receiver class*/
public class Light{
public Light(){ }
public void turnOn(){
System.out.println("The light is on");
}
public void turnOff(){
System.out.println("The light is off");
}
}
/*the Command interface*/
public interface Command{
void execute();
}
/*the Command for turning on the light*/
public class TurnOnLightCommand implements Command{
private Light theLight;
public TurnOnLightCommand(Light light){
this.theLight=light;
}
public void execute(){
theLight.turnOn();
}
}
/*the Command for turning off the light*/
public class TurnOffLightCommand implements Command{
private Light theLight;
public TurnOffLightCommand(Light light){
this.theLight=light;
}
public void execute(){
theLight.turnOff();
}
}
/*The test class*/
public class TestCommand{
public static void main(String[] args){
Light light=new Light();
Command switchUp=new TurnOnLightCommand(light);
Command switchDown=new TurnOffLightCommand(light);
Switch s=new Switch(switchUp,switchDown);
s.flipUp();
s.flipDown();
}
}
둘의 차이점?
개인적으로 둘의 쓰임새는 비슷하다고 느껴서 엄청난 혼동이 왔습니다
스텍오버플로우 형님들에 따르면
Command - Open or Close [action change]
Typically the Command pattern is used to make an object out of what needs to be done
Strategy - Quicksort or Mergesort [algo change]
The Strategy pattern, on the other hand, is used to specify how something should be done
라는데 요약해보자면
커맨드 패턴 -> 다양한 action이 있고 어떤 action'(what)을 사용하냐에 중점
전략 패턴 -> 다양한 algorithm이 있고 '어떻게'(how) 해결하냐에 중점
인거 같아요.?
reference
https://gmlwjd9405.github.io/2018/07/07/command-pattern.html
[Design Pattern] 커맨드 패턴이란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
https://stackoverflow.com/questions/4834979/difference-between-strategy-pattern-and-command-pattern
Difference between Strategy pattern and Command pattern
What is the difference between the Strategy pattern and the Command pattern? I am also looking for some examples in Java.
stackoverflow.com
| 프론트엔드에서의 레포지토리 패턴? (0) | 2022.03.18 |
|---|---|
| [행위] 책임 연쇄 패턴 (0) | 2022.03.13 |
| [행동] 중재자 패턴 (1) | 2022.03.01 |
| [구조] 데코레이터 패턴 (0) | 2022.02.28 |
| 디자인 패턴의 종류 (0) | 2022.02.24 |
프로세스를 새로 생성할때 fork 함수를 이용할 수 있습니다.
fork 함수를 호출한 프로세스는 부모 프로세스가 되고
새롭게 생성되는 프로세스는 자식 프로세스가 됩니다.
두 프로세스는 다른 pid를 가지고 독립적이게 동작합니다.

이때 Linux에서는 자식 프로세스를 생성하면 같은 메모리 공간을 공유하게 됩니다.
부모 프로세스에서 페이지 바로 C를 수정한다면 자식 프로세스에도 영향을 끼칠것입니다.
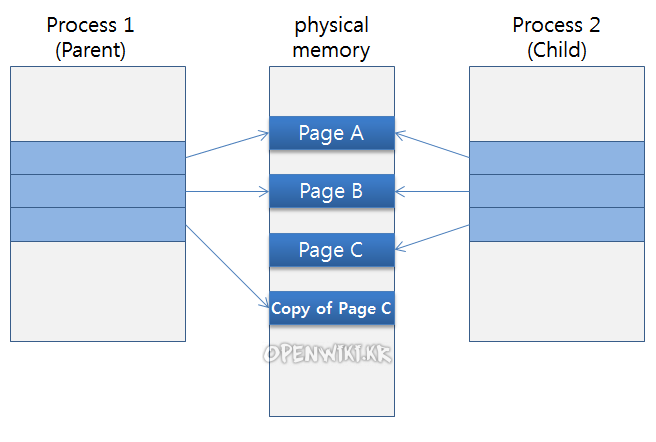
그래서 직접 변경 대신 페이지 C를 복사해서 수정(Copy on write)하는 방식으로 작동합니다.
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#include<fcntl.h>
int statofLoc; // get child process's state when child process is done
int childPid;
char **command; //get parsed words, command[0] is command,
//others option
void fatal_error(char* errorCommand) // to record error and exit
{
perror(errorCommand);
exit(-1);
}
childPid = fork();
if(childPid == 0){ // child
if(execvp(command[0], command)<0)
{
fatal_error("unknown command");
//if this function is actived,
//something is wrong
}
}
else if(childPid < 0) //error
{
fatal_error("pid ERROR");
}
else //parent
{
waitpid(childPid, &statofLoc, WUNTRACED);
//wait till child process is done.
}
wait(혹은 waitpid) 함수를 이용하면 부모 프로세스는 자식 프로세스가 종료될때까지 기다릴 수 있습니다.
wait는 다음과 같이 작동합니다.
1. 자식 프로세스가 동작 중이면 호출 차단이 차단되기 때문에 상태를 얻어올 때까지 대기
2. wait() 함수 호출자가 시그널을 받을 때까지 대기
3. 자식 프로세스가 종료된 상태라면 즉시 호출이 반환되어 상태를 얻음, 이 때 wait() 함수는 자식 프로세스의 프로세스 ID를 반환
4. 자식 프로세스가 없다면 호출이 즉시 반환되며, 에러값을 반환
부모가 먼저 자식 프로세스보다 먼저 종료되면 자식 프로세스는 고아 프로세스가 됩니다.
만약 부모가 먼저 종료되면 커널은 부모 프로세스가 누구의 부모인지 확인하고 자식 프로세스들의 부모 프로세스 ID
(ppid)들을 전부 1(init process)로 바꿔줍니다.
리눅스에서 백그라운드에서 돌아가는 데몬 프로세스를 생성하는 방법으로 해당 방식을 이용합니다.
1. fork후 부모 종료(ppid 가 1로 변경)
2. setsid로 고아 프로세스를 세션 리더로 생성
3. etc...
고아 프로세스가 종료되면 init process가 wait를 호출해 좀비 프로세스가 되는것을 방지합니다.
자식 프로세스가 종료되었지만 자식 프로세스의 종료상태를 회수하지 않았을때 자식 프로세스를 좀비 프로세스라 합니다.
자식 프로세스가 exit 시스템콜을 호출하면 프로세스에 대한 메모리 & 리소스가 해제되 다른 프로세스에서 사용 가능합니다.
그런데 자식 프로세스의 정보를 알고 싶어할 수 있기 때문에 부모 프로세스의 wait system call 호출 이전까지는 최소한의 정보를 가지는 상태로 남아 있습니다.
wait로 정말로 제거되기 이전 상태를 좀비 프로세스라고 부릅니다.
그럼 fork를 어디에 쓰나요..? 보통 멀티테스킹을 위해 많이 쓰입니다.
대표적인 예시로는 shell에서
터미널에서 fork 해 자식 프로세스를 만든 다음
자식 프로세스에서 명령어를 파싱하고, exec system call을 해 명령을 처리합니다.
다만 cd(change directory)의 경우 자식 프로세스가 아니라 부모 프로세스(터미널) 자체가 움직여야 하기 때문에
cd는 예외적으로 fork를 하지않고 직접 처리합니다.
reference
COW
https://openwiki.kr/tech/copy-on-write
Copy-on-write - 기술 - 오픈위키
Copy-on-write Copy On Write란 말 그대로 작성시 이전의 내용을 Copy한다는 뜻이다. 1) Linux(Unix)에서는 자식 프로세스(child process)를 생성(fork)하면 같은 메모리 공간을 공유하게 된다. 그런데 부모 프로세
openwiki.kr
https://codetravel.tistory.com/30?category=993122
wait 함수 사용하여 자식 프로세스 종료시까지 대기하기
부모 프로세스가 fork() 함수를 사용하여 자식 프로세스를 생성하였을 때, fork() 함수가 리턴되는 시점부터 2개의 프로세스가 동작하게 됩니다. 부모 프로세스가 자식 프로세스의 종료 상태를 얻
codetravel.tistory.com
데몬 프로세스
https://kukuta.tistory.com/386
[Linux] 데몬(Daemon) 프로세스 만들기
데몬(daemon)이란? '데몬(daemon)' 프로세스는 리눅스 운영 체제서 사용하는 프로세스의 일종으로써, 시스템 시작이 시작할 때 그 생명을 시작하여, 우리가 알지 못하는 백그라운드에서 자신의 할 일
kukuta.tistory.com
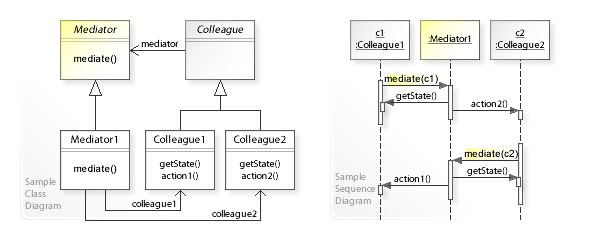
객체지향 모델에서는 객체를 구성할때 행동을 여러 객체로 분산시켜 처리하도록 권하고 있습니다(SRP)
그러다보니 시스템의 객체 분할이 객체 간 상호종속을 유발하고 이때문에 재사용성이 저하되거나 결합도가 증가할 수 있습니다.
그러면 객체는 독립적이야한다는 객체의 특성이 유명무실해질 수 있는데 객체들간의 직접적 통신을 제한하고
중재자 객체를 통해 서로 양방향 통신하게 하는 디자인 패턴입니다.
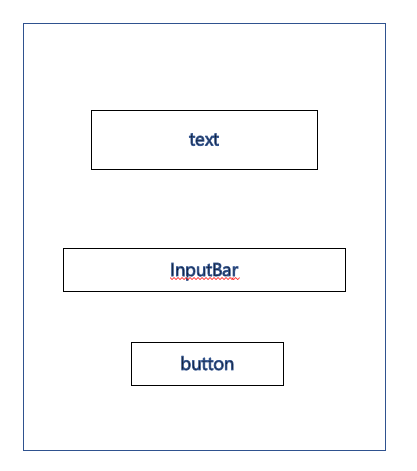
예를 들어 숫자를 increment하는 단순한 board를 만든다고 해봅시다.
text class, InputBar class, button class가 있고 서로 상호작용하지 않고 mediator 패턴으로 구현해봅시다.
역할은 단순하게
text : 지금 숫자가 얼만지 보여줍니다(show)
button : 누를때마다 숫자가 1씩 증가합니다
혹은 reset 가능합니다
InputBar : input으로 넣은 숫자로 갱신됩니다.
class Button {
constructor(mediator) {
this.mediator = mediator;
this.points = 0;
}
increment() {
this.mediator.increment();
}
reset() {
this.mediator.reset();
}
}
class InputBar {
constructor(mediator) {
this.mediator = mediator;
}
update(val) {
this.mediator.update(val);
}
}
class TextBar {
constructor(mediator) {
this.text = 0;
this.mediator = mediator;
}
setText(val) {
this.text = val;
}
show() {
this.mediator.show(this.text);
}
}
mediator 객체는 다음과 같습니다.
class BoardMediator extends Mediator {
constructor() {
this.button = new Button(this);
this.inputBar = new InputBar(this);
this.textBar = new TextBar(this);
this.points = 0;
}
increment() {
this.points += 1;
this.textBar.setText(this.points);
console.log(`increment ${this.points}`);
}
update(val) {
this.points = val;
this.textBar.setText(this.points);
console.log(`update ${this.points}`);
}
reset() {
this.points = 0;
this.textBar.setText(this.points);
console.log(`reset ${this.points}`);
}
show(val) {
console.log(`show ${val}`);
}
}
실행을 시뮬레이션 해보았을때
const med = new BoardMediator();
// click mocking event
med.button.increment();
med.button.increment();
med.button.reset();
med.button.increment();
med.inputBar.update(10);
med.button.increment();
med.textBar.show();
(인터넷을 뒤져보니 mediator 구조에 emit 처럼 observer pattern을 하나 더 끼워넣은 구조도 많이 보이던데 그런 방식도 괜찮은거 같아요)
객체간 통신(N:M)을 객체끼리 직접 상호작용하는게 아니라 mediator 객체를 통해서 실행시키므로 결합도를 여러개의 1:N 정도로 크게 줄였습니다.
단점으로는
중재자 객체가 엄청 비대해질 가능성이 있겠죠.
또한 비대해지면 유지보수가 힘들어질 느낌이 듭니다.
느낌상
observer pattern은 1:N이고 단방향
퍼사드 패턴은 N:M이고 중재자 패턴이랑 비슷한 용도로 쓰이기는 하는데
단방향이고 관계를 단순화하고 통합된 구조에 좀 더 관심이 있는 구조
(한 이벤트가 발생하면 내부 객체들이 정해진 구조에 따라서 알맞게 제어되고 실행되는 통합된 구조를 만드는데 관심이 있는 구조)
그리고 mediator 패턴은 N:M이고 양방향을 가질 수 있는 구조 느낌?
reference
GOF의 디자인 패턴
| 프론트엔드에서의 레포지토리 패턴? (0) | 2022.03.18 |
|---|---|
| [행위] 책임 연쇄 패턴 (0) | 2022.03.13 |
| [행위] 전략 패턴 & 커맨드 패턴 (0) | 2022.03.07 |
| [구조] 데코레이터 패턴 (0) | 2022.02.28 |
| 디자인 패턴의 종류 (0) | 2022.02.24 |

새로운 서비스의 추가가 필요할때 일반적으로 상속을 이용합니다.
1. 나중 추가사항이 생긴다면 superclass를 수정하고 기능을 집어넣어야 합니다.
2. 1번으로 인하여 superclass는 비대해지고
SOLID의 SRP를 위반합니다. (어떤 특정 subClass A에서만 사용하는 메소드가 B, C에도 상속됩니다.)
그래서 OCP의 컨셉을 활용하여 해결하려고 시도하는 디자인 패턴입니다.
class Food {
add() {
//재료 추가
}
}
class Ramen extends Food {
addKelp() {}
addNoodle() {}
add() {
this.addNoodle();
this.addKelp();
}
}
그런데 라면의 인기가 높아져서 라면에 온갖 고추장, 치즈, 짜장, 곰탕등 소스를 집어넣기 시작했습니다.
입니다.
그래서 데코레이터를 사용해서 치즈짜장라면과 치즈곰탕라면을..
상속을 사용하지 않고 데코레이터를 사용해서 구현해봅시다...
(글 쓰면서 뭔가 내용이 산으로 가는 느낌인데..?)
class Food {
add() {
//재료 추가
}
}
class Ramen extends Food {
addKelp() {
return 'add Kelp ';
}
addNoodle() {
return 'add noodle ';
}
assemble() {
return this.addNoodle() + this.addKelp();
}
}
class RamenDecorator extends Food {
constructor(Ramen) {
super();
this.Ramen = Ramen;
}
assemble() {
return this.Ramen.assemble();
}
}
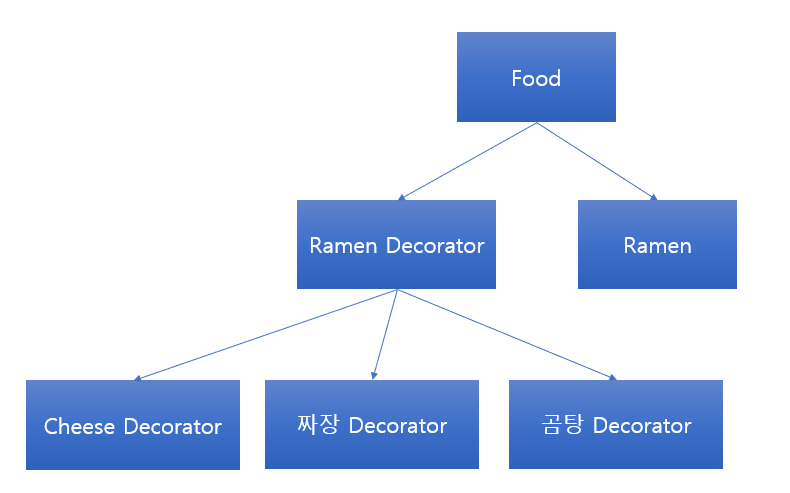
우선 Base가 되는 Ramen과 Ramen Decorator입니다.
RamenDecorator는 만들고 싶은 Ramen을 주입받아 조립해 사용합니다.
치즈라면을 일단 만들어 봅시다.
class CheeseRamenDecorator extends RamenDecorator {
addCheese() {
return 'add cheese';
}
assemble() {
return super.assemble() + this.addCheese();
}
}
const CheeseRamen = new CheeseRamenDecorator(new Ramen());
console.log(CheeseRamen.assemble());
그림으로 보면 이런 상태입니다.

$ node test.js
add noodle add Kelp add cheese코드를 실제로 돌려보면 잘 적용된걸 확인할 수 있습니다.
class BlackbeanSauceRamenDecorator extends RamenDecorator {
addBlackbeanSauce() {
return 'add BlackbeanSauce';
}
assemble() {
return super.assemble() + this.addBlackbeanSauce();
}
}
class BeefBoneSoupRamenDecorator extends RamenDecorator {
addBeefBoneSoup() {
return 'add BeefBoneSoup';
}
assemble() {
return super.assemble() + this.addBeefBoneSoup();
}
}
const CheeseRamen = new CheeseRamenDecorator(new Ramen());
console.log(CheeseRamen.assemble());
const CheeseBlackbeanSauceRamen = new BlackbeanSauceRamenDecorator(
new CheeseRamenDecorator(new Ramen()),
);
const CheeseBeefBoneSoupRamen = new BeefBoneSoupRamenDecorator(
new CheeseRamenDecorator(new Ramen()),
);
console.log(CheeseBlackbeanSauceRamen.assemble());
console.log(CheeseBeefBoneSoupRamen.assemble());아.. 라면 이름 예시를 잘못들었는데 지금 돌이킬순 없는거 같아요..
그림으로 보면 이런상태입니다.
add noodle add Kelp add cheeseadd BlackbeanSauce
add noodle add Kelp add cheeseadd BeefBoneSoup코드를 실제로 돌려보면 잘 적용된걸 확인할 수 있습니다.
그리고 상속으로 구현했을때보다 훨씬 깨끗해진걸 볼 수 있습니다.
지금은 조합 예시가 2~3개이지만 프로그램이 발전되며 조합이 수십~수백가지로 늘어났을때에도 상속보다 유연하게 처리 가능해진걸 확인할 수 있었습니다.
tmi 하나 하자면.. K사 기술면접에서 super class에 공통 함수를 놔둔다면 안쓰이는 subclass에서는 이것을 어떻게 처리해야할것인가라는 질문이 나왔었는데 그 당시에는 답변을 못했다가 오늘 알게됬네요 ㅠㅠ
https://gmlwjd9405.github.io/2018/07/09/decorator-pattern.html
[Design Pattern] 데코레이터 패턴이란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
https://steady-coding.tistory.com/391
[디자인 패턴] 데코레이터(Decorater) 패턴이란?
안녕하세요? 제이온입니다. 저번 시간에는 상태 패턴에 대해서 알아 보았습니다. 오늘은 데코레이터 패턴을 설명하겠습니다. 데코레이터(Decorater) 패턴 데코레이터 패턴은 객체에 추가적인 요건
steady-coding.tistory.com
| 프론트엔드에서의 레포지토리 패턴? (0) | 2022.03.18 |
|---|---|
| [행위] 책임 연쇄 패턴 (0) | 2022.03.13 |
| [행위] 전략 패턴 & 커맨드 패턴 (0) | 2022.03.07 |
| [행동] 중재자 패턴 (1) | 2022.03.01 |
| 디자인 패턴의 종류 (0) | 2022.02.24 |
엄청 헷갈리는 개념이라 메모해두려고 한다.

URI (Uniform Resource Identifiter - 통합 자원 식별자)
웹 기술에서 사용하는 논리적 or 물리적 리소스를 식별하는 고유한 문자열 시퀀스
주소보다는 '식별자'의 개념
URL (Uniform Resource Locator)
네트워크 상에서 웹 리소스에 대한 참조
흔히 웹 주소라고 한다.
우리가 주로 쓰는 주소가 URL
URL은 URI의 서브셋이다.
URI - 식별자
URL - 위치
URN (Uniform resource name)
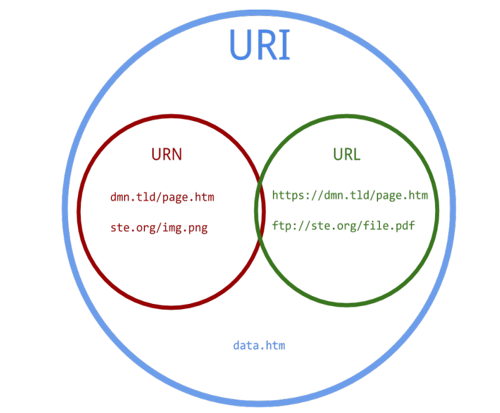
URI의 특정 포맷중 하나로 이름으로 리소스를 특정하는 URI
프로토콜을 제외하고 리소스의 name 을 가리키는데 사용
URN에는 접근 방법 & 위치가 표기 X
참고) URL 구조
scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment]
scheme : 사용할 프로토콜을 뜻하며 웹에서는 http 또는 https를 사용
user와 password : (서버에 있는) 데이터에 접근하기 위한 사용자의 이름과 비밀번호
host와 port : 접근할 대상(서버)의 호스트명과 포트번호
path : 접근할 대상(서버)의 경로에 대한 상세 정보
query : 접근할 대상에 전달하는 추가적인 정보 (파라미터)
fragment : 메인 리소스 내에 존재하는 서브 리소스에 접근할 때 이를 식별하기 위한 정보
reference
https://www.charlezz.com/?p=44767
URI랑 URL 차이점이 뭔데? | 찰스의 안드로이드
URI 그리고 URL을 혼용해서 사용하는 경우가 있다. 대부분의 경우 문제가 없지만 정확하게 이 둘의 차이점이 존재한다. 그러므로 각 용어의 정의와 용도에 대해서 알아본다. URI URI는 특정 리소스
www.charlezz.com
https://mygumi.tistory.com/139
URI vs URL vs URN :: 마이구미
이번 글은 URI, URL, URN 을 다뤄본다. URI와 URL은 아직도 많이 혼동되고 있다. 우리는 대부분 URL이라는 표현을 하고 있다. 우리가 보고 있고, 사용하고 있는 대부분이 사실 URL이기 때문이다. URI, URL, U
mygumi.tistory.com
| AnyCast란? (0) | 2022.04.11 |
|---|---|
| HTTP 메소드 멱등성, 안전한 메소드 (0) | 2022.01.31 |
| [TCP] 3-way handshake와 4-way handshake (0) | 2022.01.23 |
| Pooling, Long Pooling, Streaming (0) | 2022.01.23 |
개인적으로 DB 내용은 어렵기도 하고 안쓰고 있으면 자꾸 까먹는거 같습니다.
이 블로그의 주 목적이기도 하고 메모용으로 간단하게 글을 써보려 합니다.
*틀린게 있으면 피드백 주시면 감사하겠습니다!
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
1000페이지의 책이 있다고 쳐봅시다. 특정 키워드를 찾고 싶은데 1쪽부터 1000쪽까지 전부 순회하며 찾으려면 매우 큰 시간 낭비일것입니다.
그래서 책에는 키워드를 빨리 찾기 위해서 보통 맨뒤에 색인이 있습니다.
데이터베이스에서도 인덱스는 책의 색인과 비슷한 역할을 한다고 보면 좋습니다.
(보통 Index는 PK에 기본적으로 걸려있습니다.)
Index의 구조
Balanced Tree인 B+(B) tree를 많이 사용합니다.
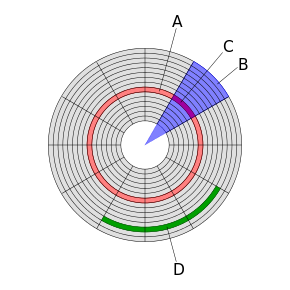
왜 tree 형태냐면 하드 디스크에서 데이터를 가져올때 섹터 단위(block 단위)로 가져오게 되는데 데이터를 효율적으로 관리하기 위해서 포인터로 참조하는 트리 형태를 띄게 됩니다.
* b tree는 모든 노드에 key와 데이터를 가지지만 B+ tree는
branch node에서는 leaf node에 대한 key를 가지고, leaf node에만 데이터를 가집니다.
Index의 장점
- 테이블 조회 속도 & 성능 향상
- 시스템 부하 감소
Index의 단점
- 인덱스를 사용하기 위해 대략 10%의 추가 저장공간이 필요하다
- 잘못 사용할 경우 성능 저하
- index 관리를 위해 추가 작업 필요
보통 create, update, delete는 빈번하게 일어나지 않고 조회(select)만 자주 일어나는 속성에 사용하는게 좋습니다
-> DELETE, UPDATE 시 인덱스를 '사용하지 않음' 처리
빈번하게 DELETE, UPDATE가 일어난다면 인덱스의 크기가 매우 커져서 오히려 성능이 줄어든다.
* select문에서 like '%문자' 같이 %를 앞에 넣어서 사용하는 경우 index를 타지않아서
검색 구현시 형태소 분석이나 elasticsearch를 사용하는것을 권장한다고 합니다
사용하면 좋은경우
- 규모가 매우 큰 테이블
- INSERT, UPDATE, DELETE가 빈번하지 않은 컬럼
- 자주 SELECT문(특히 join, where, order by)에 쓰이는 컬럼
- 데이터의 중복도가 낮은(=cardinality가 높은) 테이블
- 데이터 분포도 10~15%(1/해당 컬럼의 distinct 데이터 개수 * 100)인 칼럼
Cardinality란?
전체 행에 대한 특정 컬럼의 중복 수치를 나타내는 지표입니다
-> 중복도 낮다 = 카다널리티 높다.
-> 중복도 높다 = 카다널리티 낮다.
중복도는 어떤 절대적인 수치가 아니라 '상대'적인 수치입니다.
| id | name | location |
| 1 | park | seoul |
| 2 | lee | seoul |
| 3 | park | busan |
| 4 | kim | busan |
id가 distanct값이 4개이므로 가장 카다널리티가 높습니다.
name은 distant 값이 3개이므로 id보다는 카다널리티가 낮고, location보다는 카다널리티가 높습니다.
location은 distant 값이 2개이므로 가장 카다널리티가 낮습니다.
인덱스를 걸때 중복이 최대한 없어야 데이터가 많이 걸러질것입니다. (중복이 많을수록 full scan에 가까워짐)
그래서 카다널리티가 높은 컬럼을 인덱스 우선순위로 추천한다고 합니다.
Clustered Index
Index를 생성할때 데이터 페이지 전체를 물리적으로 재배열 합니다.
테이블 당 한개만 존재합니다.
-> 가장 효율적인 칼럼을 Clustered Index로 지정
테이블 크기의 3%정도 추천
Non-Clustered Index
군집화 되어있지 않은 인덱스 타입? (순서대로 정렬되있지 않다)
물리적으로 데이터를 배열하지 않고, 별도의 장소에 데이터 페이지가 구성됩니다.
테이블 당 여러개 존재 가능합니다.
Non-clusered index는 clustered Index보다 검색 속도는 느리지만 입력/수정/삭제는 더 빠릅니다.
(clustered Index의 경우 그 반대)
테이블 크기의 20%정도 추천
reference
index
https://mangkyu.tistory.com/96
[Database] 인덱스(index)란?
1. 인덱스(Index)란? [ 인덱스(index)란? ] 인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는
mangkyu.tistory.com
b tree
https://velog.io/@seanlion/btree
B트리,B+트리, B*트리 개념 정리
오늘은 트리 종류 중 하나인 B트리 시리즈를 정리해보려고 합니다. 이 포스팅에서는 B트리 시리즈 개념에 대해서 다룹니다.
velog.io
카디널리티
https://itholic.github.io/database-cardinality/
[database] 카디널리티(cardinality)란?
cardinality
itholic.github.io
내가 이걸 이해하고 있나? 싶어서
책읽는걸 그만두고 다른걸 해보다가 다시 내가 정리한 글들을 읽어봤다
체감상 10~30%만 실제로 응용하고 나머지는 안하고 있는 기분인데
%를 더 끌어올리게 노력해야겠다.
* SOLID
S : SRP(Single Responsibility Principle, 단일책임원칙)
하나의 객체는 하나의 책임(객체간 영향을 최소화하고 한가지 동작만을 수행)만을 가지도록 설계.
O : OCP(Open Closed Principle, 개방폐쇄원칙)
변경에는 닫혀있고 개방에는 열려있다.
→ 기존의 코드를 변경하지 않으면서 기능을 추가할 수 있도록 로직이 설계되어야 한다.
→ 클래스, 객체를 변경하지 않고도 클래스 환경을 변화할 수 있도록 구성한다.
L : LSP(Liskov Substitution Principle)
부모 클래스와 자식 클래스 간의 일관성이 있어야 한다.
→ 클래스를 재정의하지 않으며, 자식 클래스는 최소한 부모 클래스의 행위는 수행할 수 있어야 한다.
I : ISP(Interface Segregation Principle)
구체화보다는 추상화
→ 범용 인터페이스로 인해 여러 클라이언트(클래스)가 영향을 받기 보다는, 개별적인 클라이언트에 특화되어 서로의 영향을 최소화할 수 있도록 구성
D : DIP(Depedency Inversion Principle)
의존관계 역전 원칙
상위 계층(정책 결정)이 하위 계층(세부 사항)에 의존하는 전통적인 의존관계를 반전(역전)
→ 상위 모듈은 하위 모듈의 구현 내용에 의존하면 안 되고 상위 모듈과 하위 모듈 모두 추상화된 내용에 의존
깨끗한 클래스를 만드는법에 대해 다루는 챕터
그렇다면 깨끗한 클래스란?
클래스 외부 사용자는 사용하면서 내부 구현을 알 필요가 없고, 알아야할 이유도 없다.
클래스에서 꺼내와서 데이터 처리 X
객체에게 처리할 행위(method) 요청 O
캡슐화를 유지해야 좋은 클래스
풀어주는건 최후의 수단?
클래스는 함수와 마찬가지로 하나의 역할만(SRP), 작은 크기
- 만능 클래스보다는 하나의 책임
- 이름은 해당 클래스의 책임
- 모호한 이름 금지(Processor, Manager, Super 등) -> 여러 역할을 한다는걸 내포
- and, but 등 사용금지 -> 여러 역할을 한다는것 내포
보통 응집도를 높은 클래스 선호
클래스에 속한 메소드, 변수가 서로 의존하며 논리적인 단위로 묶인다
-> 큰 함수(클래스)를 여러개의 작은 역할로 나누면 응집도가 높아짐
상세한 구현은 구현 요구사항이 바뀔때마다 위험에 빠진다 -> 인터페이스 & 추상 클래스를 통해
구현
클래스가 SRP, OCP 등 SOLID 원칙을 잘 만족했다면 요구사항이 변경되어도 유연한 대처가 가능
결합도가 낮다 -> 변경에 영향받는 클래스가 격리되어 있어서 대처가 유연하다
ex) 레포지토리 패턴
https://0391kjy.tistory.com/39
Repository Pattern 이해하기
Repository Pattern? Repository(리포지토리) 패턴은 디자인 패턴 중 하나로, 데이터가 있는 여러 저장소(Local, Remote)를 추상화하여 중앙 집중처리 방식을 구성하고, 데이터를 사용하는 로직을 분리시키기
0391kjy.tistory.com
템플릿 메소드 패턴
https://gmlwjd9405.github.io/2018/07/13/template-method-pattern.html
| cleancode - unit test (0) | 2022.01.25 |
|---|---|
| clean code - 경계 (0) | 2022.01.24 |
| cleancode - 오류처리 (0) | 2022.01.22 |
| cleancode - 객체와 자료구조 (0) | 2022.01.21 |
| clean code - 주석 & 형식 맞추기 (0) | 2022.01.20 |

1. 생성(Creational) 패턴
객체 생성 방식에 대한 패턴
생성 & 조합을 캡슐화해 특정 객체가 생성-변경되도 프로그램 구조에 영향을
크게 받지 않게해서 유연성 제공
2. 구조(Structural) 패턴
클래스 & 객체를 조합해 더 큰 구조를 만드는 패턴
3. 행위(Behavioural) 패턴
객체 사이 상호작용하는 방식이나 관심사를 분리하는 방법
'바퀴를 재발명하지 말자'라는 말이 있는데 구현때 소프트웨어의 복잡성을 줄이려면 아는만큼 보이는거 같아서
앞으로 조금씩이라도 디자인패턴에 대해 공부하고 기록해놓으려고 한다.
tmi로 디자인 패턴을 몰라도 경험적으로 체득하고 사용한 경우도 있기는 있었다.
reference
https://medium.com/@nitinmuteja/part-1-gang-of-four-gof-software-design-patterns-9a2d1abe4dba
Part-1 Gang of Four (GOF) Software Design Patterns
Gang Of Four Design Patterns
medium.com
https://gmlwjd9405.github.io/2018/07/06/design-pattern.html
[Design Pattern] 디자인 패턴 종류 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
| 프론트엔드에서의 레포지토리 패턴? (0) | 2022.03.18 |
|---|---|
| [행위] 책임 연쇄 패턴 (0) | 2022.03.13 |
| [행위] 전략 패턴 & 커맨드 패턴 (0) | 2022.03.07 |
| [행동] 중재자 패턴 (1) | 2022.03.01 |
| [구조] 데코레이터 패턴 (0) | 2022.02.28 |
요즘 갈 방향을 잃은 느낌이라 주의 환기 및 내가 주로 쓰던 명령어들을 복습겸 적어볼려고 한다.
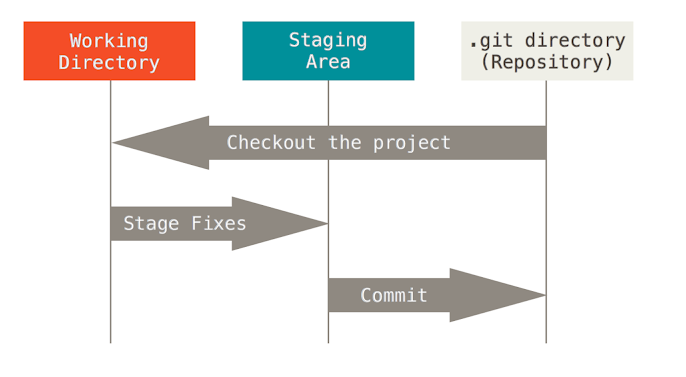
깃 공간을 크게 3가지로 나눈다면
1. Working Directory (create, update, Delete해서 작업한 파일이 반영되어 있는 디렉토리)
2. Staging Area(git add후 곧 commit 하기 이전의 디렉토리)
3. Git Directory(staging Area에 있는 작업이 commit되어 반영된 공간)
이라 할 수 있다.
이때 작업을 하다보면 각 공간(1->2, 2->3)에 잘못 반영될때도 있는데 이때 유용한 명령어가 바로 git reset이다.

git reset은 크게 3가지이다.
사용 ex) git reset --soft HEAD^1(바로 이전 커밋(head)에 반영됨)
commit을 잘못 반영했을때 Staging Area로 되돌릴 수 있는 명령어이다.
주로 commit명에 오타를 냈을때 많이 사용했다.
git reset의 default
해당 커밋의 repository~staging area의 영역에 있는 코드들을 전부 working directory에 반영한다.
(git add 이전 상태로 되돌린다)
주로 이전 커밋으로 돌아가서 staging area에 반영할 코드들을 기능별로(커밋을 나누고 싶을때)쪼개 commit할때 사용했다.
작업을 아예 rollback할때 사용한다.
구현할때 어떤 이론을 세우고 작업을 했는데 내 이론이 틀렸을때 주로 사용했다.
이걸 사용한경우는 손에 꼽히기는 한데 git reset --hard나 git 작업을 하다 잘못했을경우 롤백할 수 있는 매우 유용한 기능을 제공한다.
git rebase/git reset 등으로 커밋 이력이 삭제되었을때 git reflog를 하면 볼 수 있다
다른 브랜치에 있는 commit을 선택적으로 반영할때 사용된다.
깃은 diff 가 아니라 각 커밋이 스냅샷이긴 한데 체리픽을 할때는 diff만 반영되는거(커밋 하나의 변경점) 같다.
tmi로 경험적으로 깨달은건데(틀릴수도 있음)
local에서 작업할때 git fetch 로 remote repository의 브랜치들을 가져와 있으면 local branch에 git cherry-pick 적용이 된다는 점이다.
merge
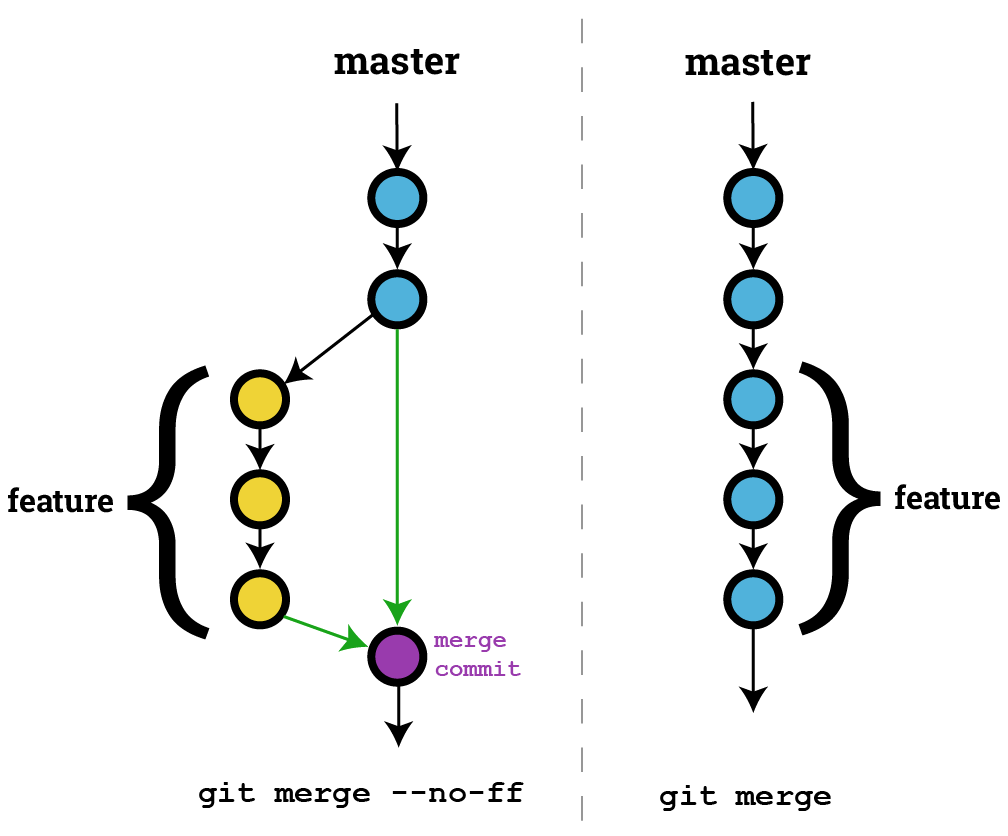
1. 3-way merge : 분기점이 있는경우 3-way merge를 해서 브랜치 두개를 합친다. (중간에 매개 commit인 merge commit이 하나 남는다)
2. fast-forward merge : 현 커밋보다 앞선 커밋들이 있는경우 fast-forward merge를 해서 앞선 커밋들을 충돌없이 따라간다.
그리고 commit id 는 그대로 남는것으로 알고 있다.
squash and merge
두개의 브랜치를 합칠때 합쳐지는 대상이 여러개의 커밋이라도 '하나의 커밋'으로 합쳐져서 반영되게 된다.
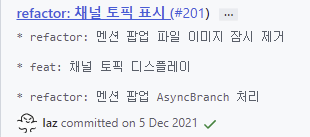
그리고 그 커밋들은 커밋 내역에 합쳐져서 보이게 된다.
rebase
일종의 되감기인데 두개의 브랜치가 한 줄로 이어지게 된다.
커밋 내역을 깔끔하게 보여줘서 rebase 팬들도 은근히 많이 있더라..
예시로
같은 부모 0 에서 시작한 1-2-3 이라는 A branch와
a-b-c라는 B 브랜치가 있다면
rebase 시 1-2-3-a-b-c 이런식으로 한줄로 된다.
그리고 Merge는 Commit ID가 보존되고, Rebase는 새로운 Commit이 생성되므로 Commit ID가 바뀐다
https://learngitbranching.js.org/?locale=ko 에서 테스트해보자.

C3에서 나온 rebase branch(C4, C5)에서 C8을 rebase 했더니 C4', C5'로 각각 새로운 commit Id가 생성된것을 확인 가능하다.
C3에서 나온 mege branch(C6, C7)에서 C9를 merge 하면 C10 가 새로 생기고(merge commit)
C9의 commit Id가 바뀌지 않고 그대로 이어진것을 확인 가능하다.
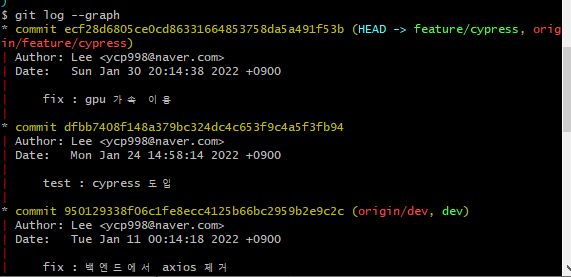
이런식으로.. cui에서 그래프 형태로 보여주게 된다
협업할때 이걸 써서 브랜치 현황을 보여주면 소스트리를 쓰는 팀원이 아주 좋아죽는다
소스트리같은 소프트웨어로 브랜치를 더 깔끔하게 보는 방법이 있으니
이런거 쓰지말고 착한 깃린이 여러분들은 이걸 쓰세여ㅠㅠ
소스트리 링크) https://www.sourcetreeapp.com/
Sourcetree | Free Git GUI for Mac and Windows
A Git GUI that offers a visual representation of your repositories. Sourcetree is a free Git client for Windows and Mac.
www.sourcetreeapp.com
reference
git reset
https://opentutorials.org/module/4032/24533
git reset --hard vs --mixed vs --soft - GIT4 - Reset & Revert
수업소개 reset은 head가 가르키는 branch가 가르키는 커밋을 변경하는 작업입니다. 이때 옵션을 --hard, --mixed, --soft 중 무엇으로 주느냐에 따라서 stage, working directory의 상태가 달라집니다. 여기서는
opentutorials.org
https://im-developer.tistory.com/182
[Git] Merge 이해하기 (Merge / Squash and Merge / Rebase and Merge)
회사에서 Git을 사용해서 형상 관리를 하고 있다. 그 동안 내가 개인 repository branch에 commit, push등을 해본 적은 많지만 다른 사람과 협업을 하면서 branch를 생성하고 master에 merge를 해본 적은 없어서
im-developer.tistory.com
Git pull doesn’t fast-forward merge, even though there are no conflicts
I just performed a git pull from my master branch on a remote repo into the branch I'm currently working on locally via the command line. Unexpectedly Vim opened. I quit Vim. Following this, I che...
stackoverflow.com
https://www.tuwlab.com/ece/22218
[GIT] 병합하고 Commit 재정렬하기: cherry-pick, rebase, merge - ECE - TUWLAB
병합과 재정렬은 대개 한 Topic(작업 단위)의 작업이 끝난 다음, 작업 내용을 Master branch에 반영해야 할 경우 수행하는 작업입니다. 새로운 Topic에 대한 작업을 할 때는 대개 Master Branch에서 새로운 B
www.tuwlab.com