자바스크립트는 싱글 쓰레드이지만, 크롬 브라우저의 탭 하나하나는 각각 하나의 프로세스이고 멀티 쓰레드 환경이다.
이전에 썼던 이벤트 루프 관련 글에서 정확히 브라우저의 내부 구조가 어떻게 구성되었는지 궁금해서 찾아보았다.
참고) 이전글
[이벤트루프] 자바스크립트에서 정확한 타이머 구현?
*잘못된 부분이 있으면 피드백 주시면 감사하겠습니다! 자바스크립트에서 타이머 이벤트를 쓸 수 있는 방법으로는 setTimeout, setInterval 두가지가 있다. 이 함수들이 어떻게 비동기를 지원할까? 자
lodado.tistory.com
컴퓨터 아키텍처 3개 레이어 - 브라우저가 돌아가는 환경
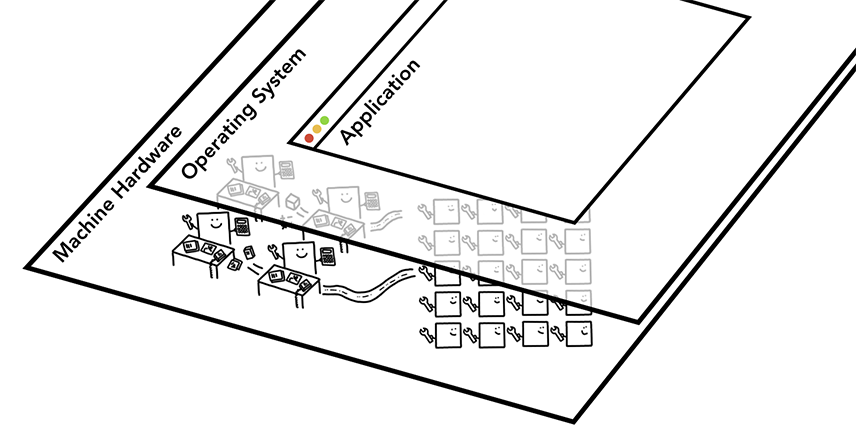
브라우저가 돌아가는 환경을 이해하기 위해서는 컴퓨터의 전반적인 구조를 이해할 필요가 있다.
Machine Hardware (스마트폰, 컴퓨터 등)
물리적으로 구현된 하드웨어 위에서 컴퓨터가 동작
실제 작업을 물리적으로 처리하는 공간이다.
최근에는 브라우저에서 단순 CPU를 넘어서서 고속 렌더링, 에니메이션을 처리하기 위해 추가적으로 GPU라는 개념이 등장했다.
CPU
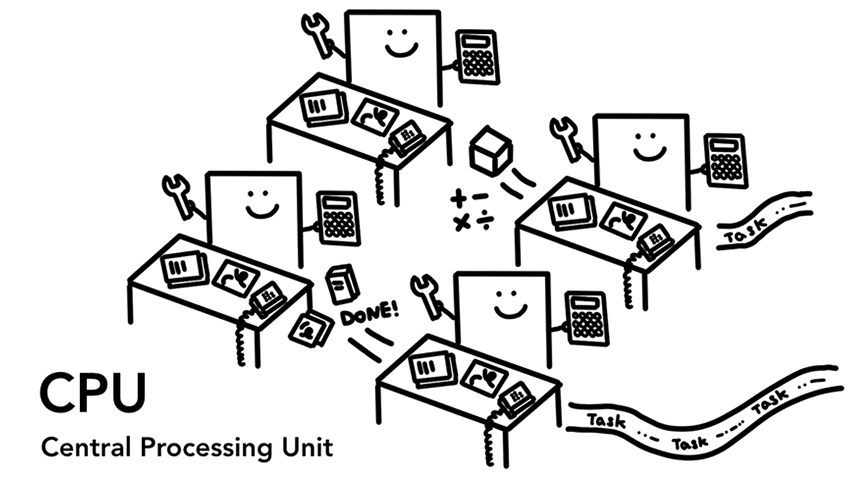
CPU는 컴퓨터의 뇌라고 볼 수 있다.
다양한 작업을 실제적으로 처리하는 공간이다.
최근엔 싱글 CPU를 넘어서서 멀티 코어등 다양한 방식을 이용해 '병렬성'을 지원하려는 연구가 활발하다.
GPU
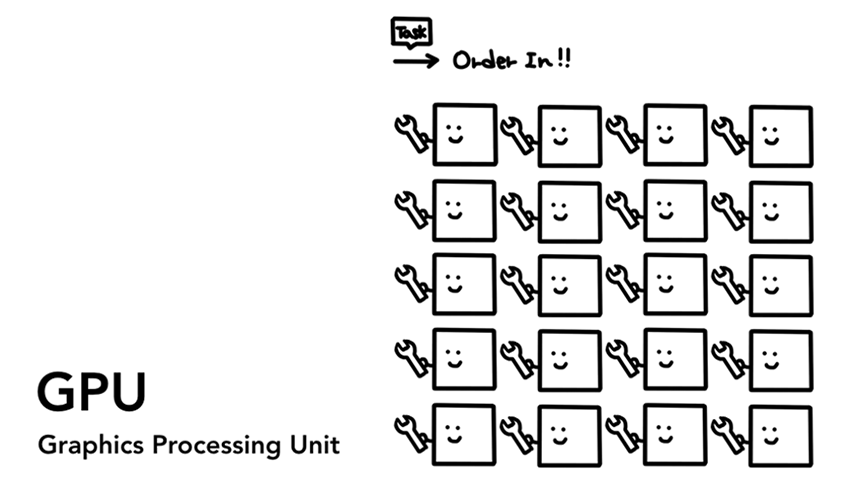
최근 브라우저에서 GPU를 이용하려는 연구도 활발하다.
GPU는 공장이라고 비유할 수 있다.
CPU는 다양한 작업을 유연하게 처리하는데 특화되어 있다면
GPU는 연산을 수많은 코어에서 동시에 처리하는데 특화되어 있다.
GPU 가속 연산 덕분에 CPU 하나로는 오래 걸릴 연산을 금방 끝낼 수 있다.
GPU가 연산을 하기 위해서는 CPU가 GPU에 데이터를 전송해줘야 연산이 가능하다.
이것을 비유하자면 CPU는 배송 트럭이라고 생각하고, GPU는 공장이라고 비유해보면 좋을것 같다.
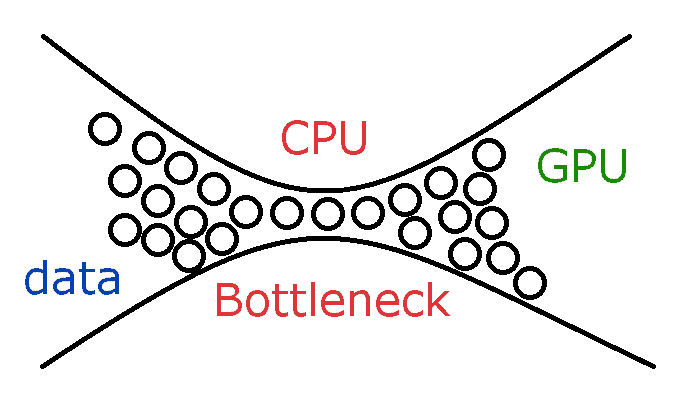
CPU가 배송(I/O, 효율적인 프로그래밍)를 빨리 해줘야 공장이 100% 효율로 가동 가능하다.
공장이 최신식(GPU의 성능이 매우 좋아도)이라도 CPU의 배송이 느리다면 제 효율을 낼 수 없다.
그리고 반대로 배송(CPU의 성능이 매우 좋아도)이 엄청 빨라도 공장의 효율이 좋지 않다면 제 효율을 낼 수 없다.
요약하자면 둘 다 중요하다.
안드로이드 같은 경우 웹앱을 사용할 경우
GPU 연산이 좋다고 모든 연산을 위임하다보면 위 GPU Bottleneck 현상 혹은 너무 많은 작업으로 오히려 CPU만 사용할때보다 느려질 수 있다.
그리고 하드웨어적인 한계가 있기 때문에 CPU, GPU의 성능을 아무리 올려도 언젠간 한계에 부딫치게 된다.
프론트엔드 엔지니어가 관여할 수 있는 부분은 '렌더링 최적화' 등 주어진 자원 내에 최대의 효율을 내는게 주 업무다.
Operating System (윈도우, 리눅스, 안드로이드 등)
소프트웨어적으로 구현된 운영체제 위에서 어플리케이션이 동작
(운영체제는 하드웨어와 이용자 사이에서 쉽게 이용할 수 있도록 인터페이스 역할을 한다. 윈도우가 왜 이름이 '윈도우'인지 생각해보면 좋을듯!)
Application (브라우저 - 크롬, 오페라 등)
우리가 사용하는 브라우저 어플리케이션이다. 운영체제가 지시하는 메커니즘에 따라 CPU & GPU를 동작 시키게 요청한다.
이 동작(프로그래밍)을 잘 시키냐에 따라 브라우저의 제 성능을 이끌어낼 수 있다.
프로세스 & 쓰레드
그리고 브라우저 아키텍처를 이해하기 이전에 프로세스 & 쓰레드 구조를 이해할 필요가 있다.
이 부분은 면접 단골질문이기도 하고 학교에서 많이 배우므로 간략하게 설명하고 넘어가겠다.
프로세스
프로세스는 운영체제로부터 자원을 할당받은 작업의 단위이다.
즉, 어플리케이션 하나가 프로세스 하나가 될 수 있다.
참고) 프로그램에 대해
프로그램은 어떤 작업을 위해 실행 할 수 있는 파일을 말하며 메모리구조에서 code 영역에 있는 실제 물리적 파일을 뜻한다.
프로세스는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 뜻하며 메모리에 올라와 실행되고 있는 프로그램의 인스턴스이다.
즉, 프로그램(passive) <-> 프로세스(active)관계라고 할 수 있다.
쓰레드
쓰레드는 프로세스 내에서 운영체제로부터 할당받는 자원을 실행하는 단위이다.
프로세스 내부에서 여러개가 생길 수 있다.
그외 자세한 정보는 다음 링크 추천
https://gmlwjd9405.github.io/2018/09/14/process-vs-thread.html
[OS] 프로세스와 스레드의 차이 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
프로세스와 쓰레드 생성 과정
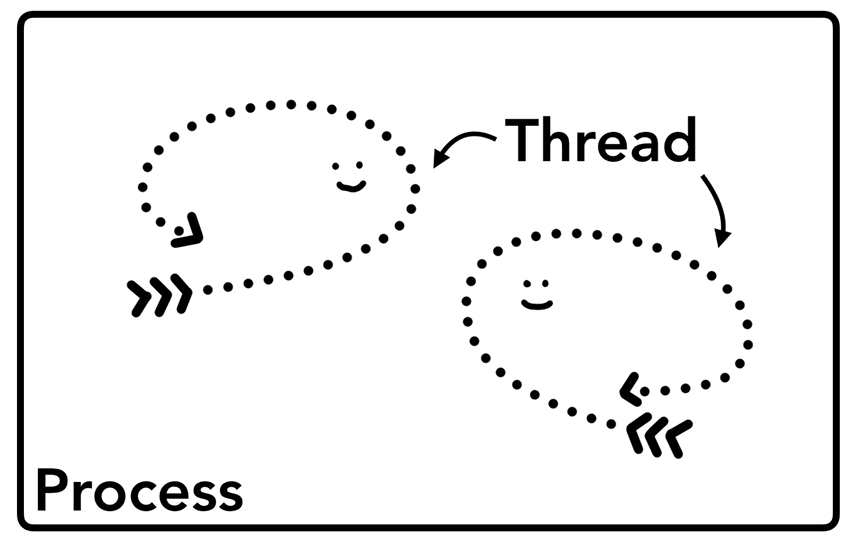
어플리케이션이 실행되면 프로세스가 생성되고,
프로세스는 작업을 위해 쓰레드(들)을 생성 할 수 있다.
그리고 OS는 프로세스에게 메모리 한 조각을 주고 모든 상태 정보를 고유 메모리 공간에 저장할 수 있게 한다. 어플리케이션이 끝나면 프로세스도 사라지고 OS가 메모리를 해제한다.
(개인적 생각으로 여기서 말하는 메모리는 RAM 메모리를 뜻하는것으로 추론된다.)
프로세스간 통신 - Inter Process Communication (IPC)
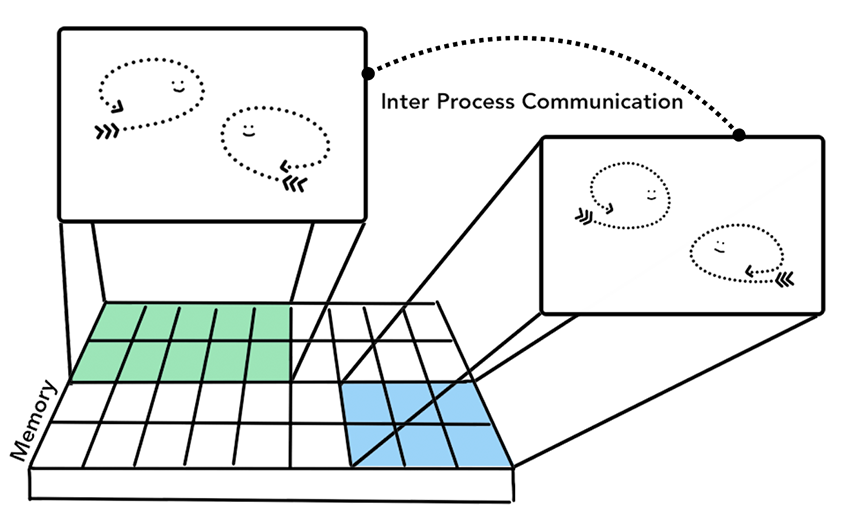
그리고 프로세스는 다른 프로세스에게 별도의 작업을 수행하도록 요청 혹은 통신이 가능하다. 많은 어플리케이션이 이 방식을 채택하고 있어 워커 프로세스가 무응답 상태에 빠지더라도 어플리케이션의 다른 부분을 수행하고 있는 프로세스들을 종료할 필요 없이 해당 프로세스만 재시작할 수 있다.
IPC에 대한 정보는 다음 링크 추천
https://jwprogramming.tistory.com/54
IPC의 종류와 특징
IPC(Inter Process Communication) - 프로세스 간 통신에 대하여 종류와 특징들에 대하여 살펴보겠습니다. [리눅스 커널 구조] - 위 그림처럼 Process는 완전히 독립된 실행객체입니다. 서로 독립되어 있다
jwprogramming.tistory.com
브라우저 아키텍처
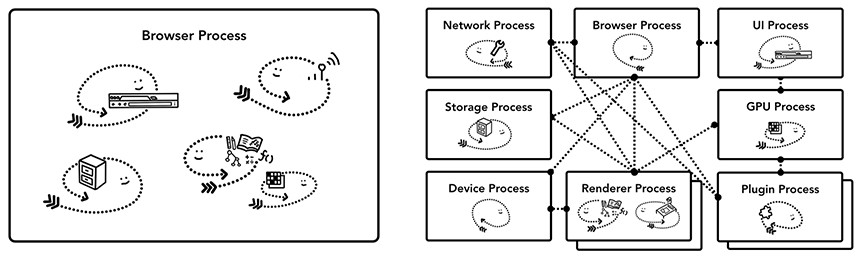
중요한점은 브라우저를 구현하는 '표준'이 없기 때문에 브라우저(IE, 오페라, 웨일, 크롬 등등..)마다 내부 작동 방식이 다를 수 있다.
그래서 공통적인 흐름을 이해하는것이 중요하다. (ex : 프로세스 & 쓰레드 구조로 동작하는구나!)
이 글은 2018년 기준 크롬 브라우저를 기준으로 설명한다.
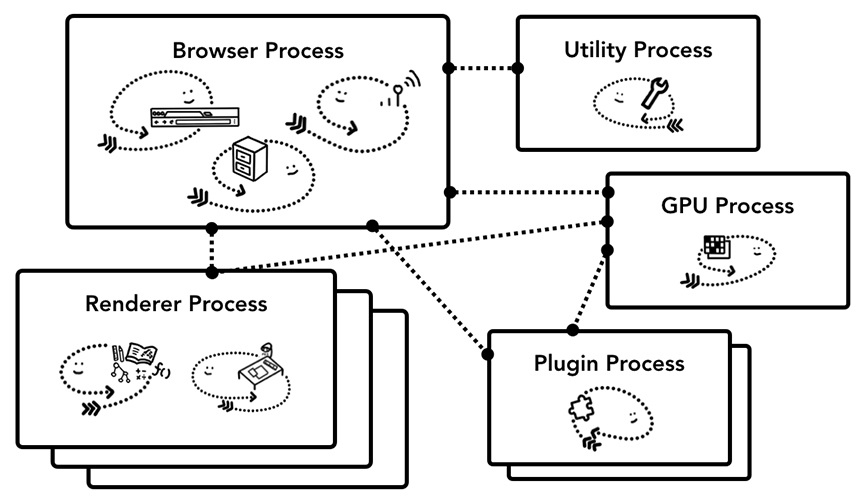
크롬은 멀티 프로세스 아키텍처를 이용한다.
*중요점 : 크롬은 여러개의 렌더러 프로세스를 가질 수 있다(보통 탭 하나당 하나).
각 중요한 프로세스의 설명은 다음과 같다.
| 프로세스 | 설명 |
| 브라우저 | 주소 창, 뒤로 및 앞으로 이동 버튼을 포함한 어플리케이션의 "chrome" 부분을 제어합니다. 또한 네트워크 요청 및 파일 액세스와 같은 웹 브라우저의 권한이 부여된 보이지 않는 부분을 제어합니다. |
| 렌더러 | 웹사이트가 디스플레이 될 때 탭 안의 모든 것 담당. |
| 플러그인 | 플래시와 같은 웹사이트가 사용하는 모든 플러그인 담당. |
| GPU | 다른 프로세스와 분리된 GPU 작업을 제어합니다. GPU는 여러 앱의 요청을 제어하고 동일한 표면에 표시하기 때문에 다른 프로세스로 분리됩니다. |
멀티 프로세스 아키텍처의 장점
그럼 왜 이런 멀티 프로세스 구조를 가질까?
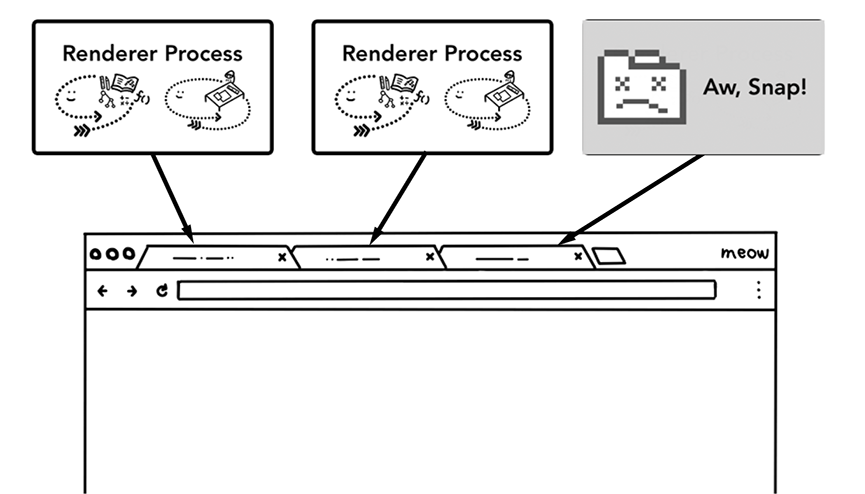
보통 탭 하나당 하나의 프로세스를 가진다.
(추가적으로 사이트 격리 옵션이 켜지고 iframe이 내부에서 실행되면 하나의 개별 Renderer 프로세스를 또 가진다)
참고)
https://blog.chromium.org/2017/05/improving-extension-security-with-out.html
Improving extension security with out-of-process iframes
Security is critical to Chrome, and many features protect Chrome users as they browse the web. Google Safe Browsing warns users away from ...
blog.chromium.org
만약 크롬이 단일 프로세스 환경이고 renderer process가 다중 쓰레드 환경이라면 한 탭이 고장이 나게 되면 모든 탭에 영향을 끼치게 된다. (메모리 영역에서 stack을 제외한 heap, code, data 등 여러 영역을 공유하기 때문?)
그런데 다중 프로세스 환경이라면 탭이 하나 고장한 경우 그냥 닫아버리고 다른 탭으로 이동하면 된다.
그외 장점으로는 보안 및 샌드박싱 (운영체제는 프로세스의 권한을 제한하는 기능을 제공)이 있다.
메모리 공간 절약
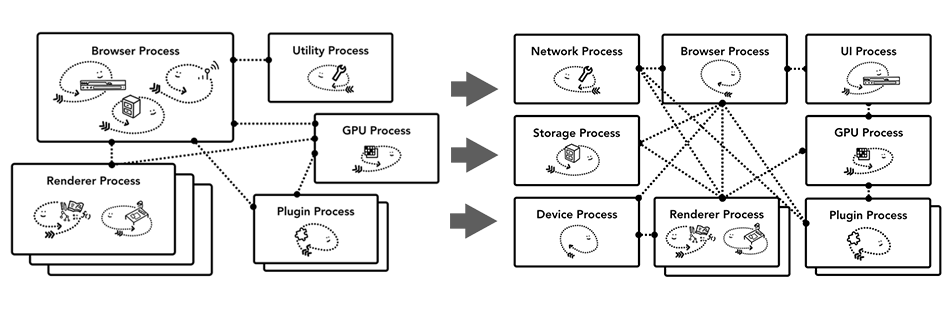
그런데 각 프로세스가 메모리 공간을 할당받아 사용하다보면 메모리 부족 현상이 일어날수도 있고 효율적이지 않다.
그래서 크롬이 고성능 장치에서 실행될 때에는 안정성을 위해 각 서비스를 별개의 프로세스로 분리하고, 자원이 부족한 장치에서는 서비스를 하나의 프로세스로 합쳐 메모리 점유를 낮추는 메커니즘이 들어가 있다.
즉, 크롬에서 최대 프로세스 개수에 제한을 두었다.
이 구조는 안드로이드에서도 구현되어 있어 유사한 프로세스를 합쳐 메모리 점유를 줄이는 방식을 실행한다.
기타 브라우저의 동작 방식
전반적으로 mutli process architecture를 따르는 듯하다.
IE8
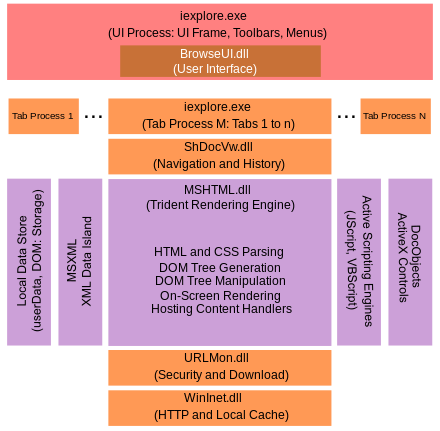
크롬의 브라우징 프로세스와 렌더링 프로세스 두개를 심플하게 가지는거 같다.
One mainframe process
Zero or multiple tab processes
tab process의 경우 RAM 크기에 따라 자동으로 크기가 조절된다.
Firefox
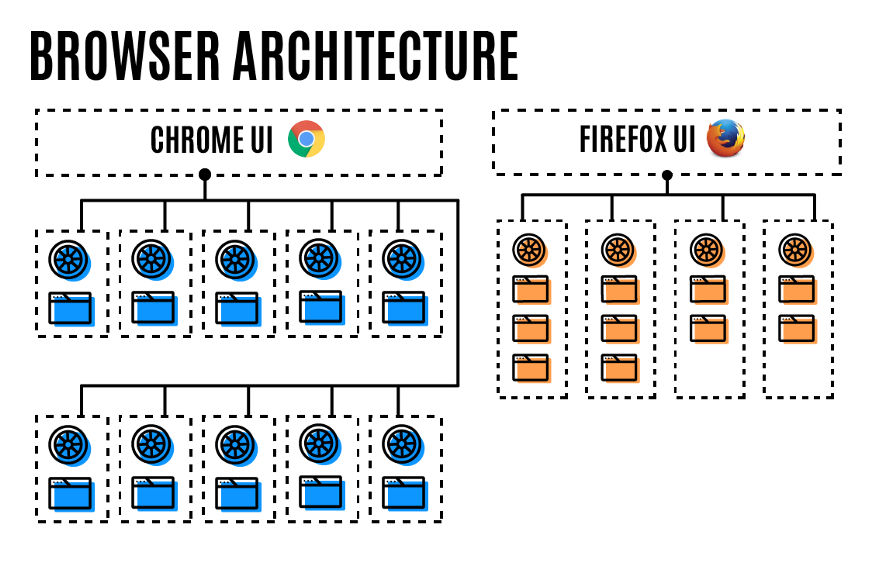
Firefox의 경우엔 멀티 프로세스 아키텍처인것은 크롬과 동일하다. 다만 4개까지의 다중 프로세스를 허용하고 이후
탭의 경우는 구글과 비슷하게 기존 프로세스 내부에서 메모리 영역을 공유한다.
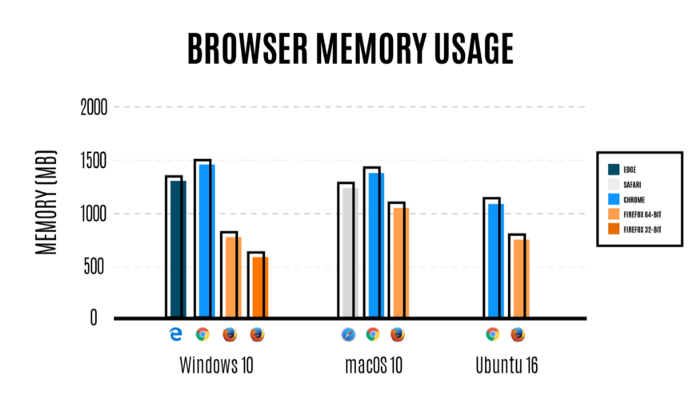
모질라의 주장에 따르면 자기들이 메모리를 제일 적게 쓴다고 하는데
프로세스를 4개까지만 만드니까 당연한 내용이다 😂
같이 읽어보면 좋을 글)
https://levelup.gitconnected.com/how-web-browsers-use-processes-and-threads-9f8f8fa23371
How web browsers use Processes and Threads
A process can be described as an application’s executing program. A thread is the one that lives inside of process and executes any part…
levelup.gitconnected.com
프론트엔드 개발자를 위한 크롬 렌더링 성능 인자 이해하기
3년 전에 개인 블로그에 적었던 글이라 이미 보신 분들도 있으리라 생각됩니다만, 미디엄에서 이전의 기술관련 글들을 같이 관리할 겸 같이 포스팅하기로 하였습니다. :)
medium.com
reference
https://wvganjana.medium.com/how-web-browsers-use-process-threads-67e156abb3c5
How web browsers use Process & Threads
As we all know Chrome and Firefox both using multi-threading in architecture. But they support it in different ways.
wvganjana.medium.com
https://www.wepc.com/tips/cpu-gpu-bottleneck/
CPU and GPU Bottleneck: A Detailed Explanation
Have you ever experienced playing a game and you get sudden FPS drop from time to time? The next second, you’re dead.. If you try to observe, these sudden
www.wepc.com
https://developers.google.com/web/updates/2018/09/inside-browser-part1?hl=ko
모던 웹 브라우저 들여다보기 (파트 1) | Web | Google Developers
브라우저에서 사용자 코드를 하이레벨 아키텍처부터 렌더링 파이프라인 세부 기능에 이르는 기능성 웹사이트로 전환하는 방법
developers.google.com
'Front-end > 브라우저' 카테고리의 다른 글
| 다국어 지원을 위하여 tailwind에서 logical property로 overwrite하기 (3) | 2025.03.04 |
|---|---|
| Cross-Origin Read Blocking(CORB) (3) | 2022.02.04 |
| 크롬 브라우저의 이벤트 핸들링 처리 (0) | 2022.02.01 |
| 브라우저의 렌더링 과정 (feat GPU) (0) | 2022.01.30 |