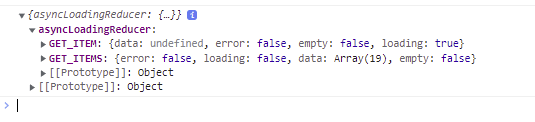
[payload] : ~~상태 를 사용해서 아까 보낸 getVaildRequestType의 파라미터마다 상태를 가질 수 있다.
예를 들어 LOADING_STATE에 지금 GET_ITEM 과 GET_ITEMS라는 type를 지정해두고 이후 redux-saga에서 실행할때 해당 type를 requestType(payload)로 받아온다면 type마다 { data, loading, error } 결과값을 가지는 상태를 가질 수 있다!
(이게 무슨말인지 혼동된다면 아래의 redux-saga까지 보고오면 이해가 빠를것 같다)
GET_ITEM, GET_ITEMS 각각 type 하나마다 { START_LOADING, FAIL_LOADING, FINISH_LOADING } case 상태(RESPONSE_STATE)를 가진다.
ex) GET_ITEMS만 ajax 요청을 받아오고 완료되었을때 상태 출력(case FINISH_LOADING), GET_ITEMS는 아직 요청을 보내지 않았다(case START_LOADING-(default)).
SUCCESS(case FINISH_LOADING)땐 아까 만든 상태에 data를 주입해서 반환해주자.
- It ensures that pages from different websites are always put into different processes.
- It also blocks the process from receiving certain types of sensitive data from other site
즉, Chrome's Site Isolation effectively makes it harder for untrusted websites to access or steal information from your accounts on other websites.
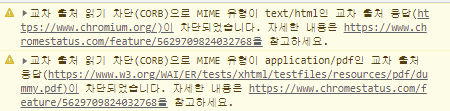
Cross-Origin Read Blocking(CORB)
Cross-Origin Read Blocking (CORB) is an algorithm that can identify and block dubious cross-origin resource loads in web browsers before they reach the web page.
For example, it will block a cross-origin text/html response requested from a <script> or <img> tag, replacing it with an empty response instead.
CORS doesn’t explicitly allow access to the resource
그리고 CORB는 위 조건을 만족한다면
renderer process가 a cross-origin data resource를 받아와 사용하는 것을 금지한다.
(a new security feature that prevents the contents ofbalance.json from ever entering the memory of the renderer process memory based on its MIME type.)
참고)
X-Content-Type-Options: nosniff는 Microsoft에서 제안하는 확장 헤더이며 웹서버가 보내는 MIME 형식 이외의 형식으로 해석을 확장하는 것을 제한하는 크로스사이트스크립트 방어법이다.
즉, nosniff 옵션이 켜있다면 브라우저는 이게 HTML, XML, JSON중 하나인것으로 Content-type 종류로 인하여 헷갈리지 않고 바로 확정 지을 수 있다.
(가끔 어떤 서버는 이미지에 대해 text/html로 잘못 분류하기도 한다. 이걸 방지 가능)
이점
CORB를 사용하면 다음과 같은 이점이 있다.
- Mark responses with the correct Content-Type header.
- out of sniffing by using the X-Content-Type-Options: nosniff header.
- 보안! (In browsers with Site Isolation, it can keep such data out of untrusted renderer processes entirely, helping even against side channel attacks like Spectre)